Go2
2.1 命名
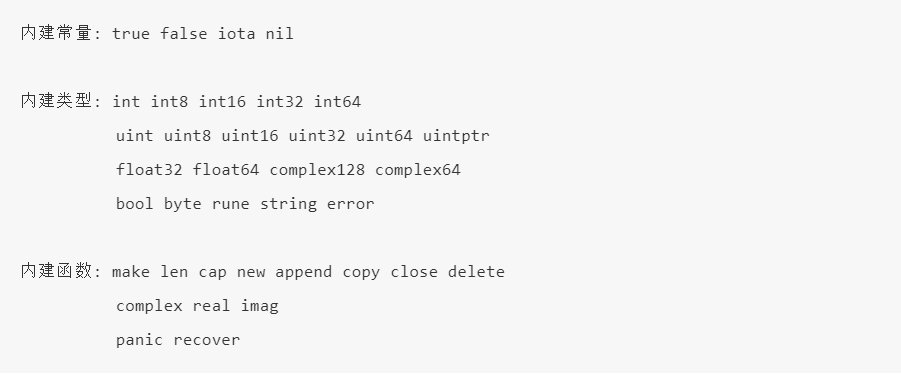
关键字及内建名字

变量的作用范围
函数内部和外部
- 如果一个名字是在函数内部定义,那么它就只在函数内部有效。
- 如果是在函数外部定义,那么将在当前包的所有文件中都可以访问。
名字的大小写
- 名字的开头字母的大小写决定了名字在包外的可见性。
- 如果一个名字是大写字母开头的(译注:必须是在函数外部定义的包级名字;包级函数名本身也是包级名字),那么它将是导出的,也就是说可以被外部的包访问
- 包本身的名字一般总是用小写字母。
- 如果一个名字是大写字母开头的(译注:必须是在函数外部定义的包级名字;包级函数名本身也是包级名字),那么它将是导出的,也就是说可以被外部的包访问
2.2 声明
- 声明语句定义了程序的各种实体对象以及部分或全部的属性。
- Go语言主要有四种类型的声明语句:
- var 变量
- const 常量
- type 类型
- func 函数实体
- 一个Go语言编写的程序对应一个或多个以.go为文件后缀名的源文件。
- 每个源文件中以包的声明语句开始,说明该源文件是属于哪个包
- 包声明语句之后是import语句导入依赖的其它包
- 然后是包一级的类型、变量、常量、函数的声明语句
- 包一级的各种类型的声明语句的顺序无关紧要
- 函数内部的名字则必须先声明之后才能使用
例子
1 | // Boiling prints the boiling point of water. |
变量
- 常量boilingF是在包一级范围声明语句声明的
- 包一级声明语句声明的名字可在整个包对应的每个源文件中访问,而不是仅仅在其声明语句所在的源文件中访问
- f和c两个变量是在main函数内部声明的声明语句声明的
- 局部声明的名字就只能在函数内部很小的范围被访问。
函数
- 一个函数的声明由一个函数名字、参数列表(由函数的调用者提供参数变量的具体值)、一个可选的返回值列表和包含函数定义的函数体组成。
- 如果函数没有返回值,那么返回值列表是省略的。
- 执行函数从函数的第一个语句开始,依次顺序执行直到遇到return返回语句,如果没有返回语句则是执行到函数末尾,然后返回到函数调用者。
2.3 变量
var声明语句
1 | var 变量名字 类型 = 表达式 |
- var声明语句可以创建一个特定类型的变量
- 给变量附加一个名字,并且设置变量的初始值
- 其中“类型”或“=
表达式”两个部分可以省略其中的一个。
- 如果省略的是类型信息,那么将根据初始化表达式来推导变量的类型信息。
- 如果初始化表达式被省略,那么将用零值初始化该变量。
- 接口或引用类型(包括slice、指针、map、chan和函数)变量对应的零值是nil
- 可以在一个声明语句中同时声明一组变量,或用一组初始化表达式声明并初始化一组变量
- 如果省略每个变量的类型,将可以声明多个类型不同的变量
1 | var i, j, k int // int, int, int |
在包级别声明的变量会在main入口函数执行前完成初始化
局部变量将在声明语句被执行到的时候完成初始化。
一组变量也可以通过调用一个函数,由函数返回的多个返回值初始化
1 | var f, err = os.Open(name) // os.Open returns a file and an error |
2.3.1 简短的变量声明
“名字 := 表达式”形式声明变量
变量的类型根据表达式来自动推导
简短变量声明被广泛用于大部分的局部变量的声明和初始化
1 | t := 0.0 |
- var形式的声明语句往往是用于需要显式指定变量类型的地方
- 或者因为变量稍后会被重新赋值而初始值无关紧要的地方。
1 | i := 100 // an int |
- 多变量同时赋值
1 | i, j := 0, 1 |
注意
- “:=”是一个变量声明语句,而“=”是一个变量赋值操作
1 | f, err := os.Open(name) |
- 简短变量声明语句中必须至少要声明一个新的变量
1 | f, err := os.Open(infile) |
- 简短变量声明语句只有对已经在同级词法域声明过的变量才和赋值操作语句等价
- 如果变量是在外部词法域声明的,那么简短变量声明语句将会在当前词法域重新声明一个新的变量。
2.3.2. 指针
一个变量对应一个保存了变量对应类型值的内存空间。
- 普通变量在声明语句创建时被绑定到一个变量名
一个指针的值是另一个变量的地址。
一个指针对应变量在内存中的存储位置
并不是每一个值都会有一个内存地址,但是对于每一个变量必然有对应的内存地址。
如果用“var x int”声明语句声明一个x变量,
- 那么&x表达式(取x变量的内存地址)将产生一个指向该整数变量的指针
- 指针对应的数据类型是
*int,指针被称之为“指向int类型的指针”。
如果指针名字为p,那么可以说“p指针指向变量x”,
或者说“p指针保存了x变量的内存地址”。
同时
*p表达式对应p指针指向的变量的值。一般
*p表达式读取指针指向的变量的值,这里为int类型的值,同时因为
*p对应一个变量,所以该表达式也可以出现在赋值语句的左边,表示更新指针所指向的变量的值。
1 | x := 1 |
- 对于聚合类型每个成员——比如结构体的每个字段、或者是数组的每个元素——也都是对应一个变量,因此可以被取地址。
- 即使变量由表达式临时生成,那么表达式也必须能接受
&取地址操作。 - 任何类型的指针的零值都是nil。
- 如果p指向某个有效变量,那么
p != nil测试为真。
- 如果p指向某个有效变量,那么
- 指针之间也是可以进行相等测试的,只有当它们指向同一个变量或全部是nil时才相等。
1 | var x, y int |
- 在Go语言中,返回函数中局部变量的地址也是安全的。
1 | var p = f() |
flag包
指针是实现标准库中flag包的关键技术,它使用命令行参数来设置对应变量的值,而这些对应命令行标志参数的变量可能会零散分布在整个程序中。
1 | // Echo4 prints its command-line arguments. |
- 调用flag.Bool函数会创建一个新的对应布尔型标志参数的变量。有三个属性
- 第一个是命令行标志参数的名字“n”,
- 然后是该标志参数的默认值(这里是false),
- 最后是该标志参数对应的描述信息。
- 程序中的
sep和n变量分别是指向对应命令行标志参数变量的指针,因此必须用*sep和*n形式的指针语法间接引用它们。
2.3.3. new函数
另一个创建变量的方法是调用内建的new函数
表达式new(T)将创建一个T类型的匿名变量
- 初始化为T类型的零值,然后返回变量地址,返回的指针类型为
*T。
- 初始化为T类型的零值,然后返回变量地址,返回的指针类型为
1 | p := new(int) // p, *int 类型, 指向匿名的 int 变量 |
- 用new创建变量和普通变量声明语句方式创建变量没有什么区别
- 除了不需要声明一个临时变量的名字外,我们还可以在表达式中使用new(T)
1 | func newInt() *int { |
- 每次调用new函数都是返回一个新的变量的地址,因此下面两个地址是不同的
1 | p := new(int) |
- 特殊情况:如果两个类型都是空的,也就是说类型的大小是0
- 例如
struct{}和[0]int,有可能有相同的地址(依赖具体的语言实现)
- 例如
- 由于new只是一个预定义的函数,它并不是一个关键字,因此我们可以将new名字重新定义为别的类型。
1 | func delta(old, new int) int { return new - old } |
2.3.4. 变量的生命周期
变量的生命周期指的是在程序运行期间变量有效存在的时间段。
对于在包一级声明的变量来说,它们的生命周期和整个程序的运行周期是一致的。
而相比之下,局部变量的生命周期则是动态的:
- 每次从创建一个新变量的声明语句开始,直到该变量不再被引用为止,然后变量的存储空间可能被回收
函数的参数变量和返回值变量都是局部变量。它们在函数每次被调用的时候创建。
Go语言的自动垃圾收集器是如何知道一个变量是何时可以被回收的呢?
- 基本的实现思路是,从每个包级的变量和每个当前运行函数的每一个局部变量开始,通过指针或引用的访问路径遍历,是否可以找到该变量。
- 如果不存在这样的访问路径,那么说明该变量是不可达的,也就是说它是否存在并不会影响程序后续的计算结果。
编译器会自动选择在栈上还是在堆上分配局部变量的存储空间,但可能令人惊讶的是,这个选择并不是由用var还是new声明变量的方式决定的
1 | var global *int |
f函数里的x变量必须在堆上分配,因为它在函数退出后依然可以通过包一级的global变量找到,虽然它是在函数内部定义的
*y并没有从函数g中逃逸,编译器可以选择在栈上分配*y的存储空间其实在任何时候,你并不需为了编写正确的代码而要考虑变量的逃逸行为,要记住的是,逃逸的变量需要额外分配内存,同时对性能的优化可能会产生细微的影响。
2.4 赋值
- 使用赋值语句可以更新一个变量的值
- 最简单的赋值语句是将要被赋值的变量放在=的左边,新值的表达式放在=的右边。
1 | x = 1 // 命名变量的赋值 |
- 特定的二元算术运算符和赋值语句的复合操作有一个简洁形式
- 数值变量也可以支持
++递增和--递减语句
1 | count[x] *= scale |
2.4.1. 元组赋值
- 元组赋值是另一种形式的赋值语句,它允许同时更新多个变量的值。
- 在赋值之前,赋值语句右边的所有表达式将会先进行求值,然后再统一更新左边对应变量的值
1 | x, y = y, x |
- 元组赋值也可以使一系列琐碎赋值更加紧凑
1 | i, j, k = 2, 3, 5 |
- 但如果表达式太复杂的话,应该尽量避免过度使用元组赋值;因为每个变量单独赋值语句的写法可读性会更好。
- 有些表达式会产生多个值,比如调用一个有多个返回值的函数。
- 当这样一个函数调用出现在元组赋值右边的表达式中时
- (译注:右边不能再有其它表达式),左边变量的数目必须和右边一致。
1 | f, err = os.Open("foo.txt") // function call returns two values |
- 通常,这类函数会用额外的返回值来表达某种错误类型
- 还有一些是用来返回布尔值,通常被称为ok。
1 | v, ok = m[key] // map lookup |
- 和变量声明一样,我们可以用下划线空白标识符
_来丢弃不需要的值。
1 | _, err = io.Copy(dst, src) // 丢弃字节数 |
2.4.2. 可赋值性
- 赋值语句是显式的赋值形式
- 但是程序中还有很多地方会发生隐式的赋值行为:
- 函数调用会隐式地将调用参数的值赋值给函数的参数变量,
- 一个返回语句会隐式地将返回操作的值赋值给结果变量,
- 一个复合类型的字面量(§4.2)也会产生赋值行为。
1 | medals := []string{"gold", "silver", "bronze"} |
- 隐式地对slice的每个元素进行赋值操作,类似这样写的行为
1 | medals[0] = "gold" |
map和chan的元素,虽然不是普通的变量,但是也有类似的隐式赋值行为。
不管是隐式还是显式地赋值,在赋值语句左边的变量和右边最终的求到的值必须有相同的数据类型。
更直白地说,只有右边的值对于左边的变量是可赋值的,赋值语句才是允许的。
nil可以赋值给任何指针或引用类型的变量
2.5. 类型
变量或表达式的类型定义了对应存储值的属性特征
- 数值在内存的存储大小(或者是元素的bit个数)
- 它们在内部是如何表达的,是否支持一些操作符
- 以及它们自己关联的方法集等
在任何程序中都会存在一些变量有着相同的内部结构,但是却表示完全不同的概念。
一个类型声明语句创建了一个新的类型名称,和现有类型具有相同的底层结构。
- 新命名的类型提供了一个方法,用来分隔不同概念的类型,这样即使它们底层类型相同也是不兼容的
1 | type 类型名字 底层类型 |
- 类型声明语句一般出现在包一级,因此如果新创建的类型名字的首字符大写,则在包外部也可以使用。
1 | // Package tempconv performs Celsius and Fahrenheit temperature computations. |
- 在这个包声明了两种类型:Celsius和Fahrenheit分别对应不同的温度单位。
- 它们虽然有着相同的底层类型float64,但是它们是不同的数据类型,因此它们不可以被相互比较或混在一个表达式运算。
类型转换
- Celsius(t)和Fahrenheit(t)是类型转换操作,它们并不是函数调用。
- 类型转换不会改变值本身,但是会使它们的语义发生变化。
- 对于每一个类型T,都有一个对应的类型转换操作T(x),用于将x转为T类型
- 如果T是指针类型,可能会需要用小括弧包装T,比如
(*int)(0) - 只有当两个类型的底层基础类型相同时,才允许这种转型操作,或者是两者都是指向相同底层结构的指针类型,这些转换只改变类型而不会影响值本身
- 如果T是指针类型,可能会需要用小括弧包装T,比如
- 数值类型之间的转型也是允许的,并且在字符串和一些特定类型的slice之间也是可以转换的
- 将一个浮点数转为整数将丢弃小数部分,将一个字符串转为
[]byte类型的slice将拷贝一个字符串数据的副本
- 将一个浮点数转为整数将丢弃小数部分,将一个字符串转为
比较
比较运算符
==和<也可以用来比较一个命名类型的变量和另一个有相同类型的变量,或有着相同底层类型的未命名类型的值之间做比较。如果两个值有着不同的类型,则不能直接进行比较:
1 | var c Celsius |
注意最后那个语句。尽管看起来像函数调用,但是Celsius(f)是类型转换操作,它并不会改变值,仅仅是改变值的类型而已
测试为真的原因是因为c和g都是零值。
下面的声明语句,Celsius类型的参数c出现在了函数名的前面,表示声明的是Celsius类型的一个名叫String的方法,该方法返回该类型对象c带着°C温度单位的字符串
1 | func (c Celsius) String() string { return fmt.Sprintf("%g°C", c) } |
- 许多类型都会定义一个String方法,因为当使用fmt包的打印方法时,将会优先使用该类型对应的String方法返回的结果打印
1 | c := FToC(212.0) |
2.6. 包和文件
- Go语言中的包和其他语言的库或模块的概念类似,目的都是为了支持模块化、封装、单独编译和代码重用
- 一个包的源代码保存在一个或多个以.go为文件后缀名的源文件中,通常一个包所在目录路径的后缀是包的导入路径
- 例如包gopl.io/ch1/helloworld对应的目录路径是$GOPATH/src/gopl.io/ch1/helloworld。
- 每个包都对应一个独立的名字空间。
- 例如,在image包中的Decode函数和在unicode/utf16包中的 Decode函数是不同的。
- 要在外部引用该函数,必须显式使用image.Decode或utf16.Decode形式访问。
- 包还可以让我们通过控制哪些名字是外部可见的来隐藏内部实现信息。
- 在Go语言中,一个简单的规则是:如果一个名字是大写字母开头的,那么该名字是导出的
例子
把变量的声明、对应的常量,还有方法都放到tempconv.go源文件中:
1 | // Package tempconv performs Celsius and Fahrenheit conversions. |
转换函数则放在另一个conv.go源文件中
1 | package tempconv |
- 每个源文件都是以包的声明语句开始,用来指明包的名字。
- 当包被导入的时候,包内的成员将通过类似tempconv.CToF的形式访问。
- 而包级别的名字,例如在一个文件声明的类型和常量,在同一个包的其他源文件也是可以直接访问的,就好像所有代码都在一个文件一样。
- 要注意的是tempconv.go源文件导入了fmt包,但是conv.go源文件并没有,因为这个源文件中的代码并没有用到fmt包。
包级别的常量名都是以大写字母开头,它们可以像tempconv.AbsoluteZeroC这样被外部代码访问:
1 | fmt.Printf("Brrrr! %v\n", tempconv.AbsoluteZeroC) // "Brrrr! -273.15°C" |
要将摄氏温度转换为华氏温度,需要先用import语句导入gopl.io/ch2/tempconv包,然后就可以使用下面的代码进行转换了:
要将摄氏温度转换为华氏温度,需要先用import语句导入gopl.io/ch2/tempconv包,然后就可以使用下面的代码进行转换了
1 | fmt.Println(tempconv.CToF(tempconv.BoilingC)) // "212°F" |
- 在每个源文件的包声明前紧跟着的注释是包注释
- 通常,包注释的第一句应该先是包的功能概要说明。一个包通常只有一个源文件有包注释
- (如果有多个包注释,目前的文档工具会根据源文件名的先后顺序将它们链接为一个包注释)。
- 如果包注释很大,通常会放到一个独立的doc.go文件中。
2.6.1. 导入包
在Go语言程序中,每个包都有一个全局唯一的导入路径
除了包的导入路径,每个包还有一个包名,包名一般是短小的名字(并不要求包名是唯一的),包名在包的声明处指定。
导入语句将导入的包绑定到一个短小的名字,然后通过该短小的名字就可以引用包中导出的全部内容。
如果导入了一个包,但是又没有使用该包将被当作一个编译错误处理
- 在这种情况下,我们需要将不必要的导入删除或注释掉
可以使用golang.org/x/tools/cmd/goimports导入工具,它可以根据需要自动添加或删除导入的包
- 许多编辑器都可以集成goimports工具,然后在保存文件的时候自动运行。
- 类似的还有gofmt工具,可以用来格式化Go源文件
2.6.2. 包的初始化
- 包的初始化首先是解决包级变量的依赖顺序,然后按照包级变量声明出现的顺序依次初始化
1 | var a = b + c // a 第三个初始化, 为 3 |
- 如果包中含有多个.go源文件,它们将按照发给编译器的顺序进行初始化
- Go语言的构建工具首先会将.go文件根据文件名排序,然后依次调用编译器编译。
- 对于在包级别声明的变量,如果有初始化表达式则用表达式初始化,还有一些没有初始化表达式的
- 例如某些表格数据初始化并不是一个简单的赋值过程。
- 在这种情况下,我们可以用一个特殊的init初始化函数来简化初始化工作。每个文件都可以包含多个init初始化函数
1 | func init() { /* ... */ } |
这样的init初始化函数除了不能被调用或引用外,其他行为和普通函数类似。
在每个文件中的init初始化函数,在程序开始执行时按照它们声明的顺序被自动调用。
每个包在解决依赖的前提下,以导入声明的顺序初始化,每个包只会被初始化一次。
- 因此,如果一个p包导入了q包,那么在p包初始化的时候可以认为q包必然已经初始化过了。
- 初始化工作是自下而上进行的,main包最后被初始化。
- 以这种方式,可以确保在main函数执行之前,所有依赖的包都已经完成初始化工作了。
2.7. 作用域
- 一个声明语句将程序中的实体和一个名字关联,比如一个函数或一个变量。
- 声明语句的作用域是指源代码中可以有效使用这个名字的范围。
作用域和声明周期的区别
- 声明语句的作用域对应的是一个源代码的文本区域;它是一个编译时的属性。
- 一个变量的生命周期是指程序运行时变量存在的有效时间段,在此时间区域内它可以被程序的其他部分引用;是一个运行时的概念。
词法块
句法块是由花括弧所包含的一系列语句,就像函数体或循环体花括弧包裹的内容一样。
句法块内部声明的名字是无法被外部块访问的。这个块决定了内部声明的名字的作用域范围
对全局的源代码来说,存在一个整体的词法块,称为全局词法块;
对于每个包;每个for、if和switch语句,也都有对应词法块;
每个switch或select的分支也有独立的词法块;
当然也包括显式书写的词法块(花括弧包含的语句)。
作用域大小
声明语句对应的词法域决定了作用域范围的大小。
对于内置的类型、函数和常量,比如int、len和true等是在全局作用域的,因此可以在整个程序中直接使用。
任何在函数外部(也就是包级语法域)声明的名字可以在同一个包的任何源文件中访问的
一个程序可能包含多个同名的声明,只要它们在不同的词法域就没有关系。
当编译器遇到一个名字引用时,它会对其定义进行查找,查找过程从最内层的词法域向全局的作用域进行。
- 如果查找失败,则报告“未声明的名字”这样的错误。
- 如果该名字在内部和外部的块分别声明过,则内部块的声明首先被找到。
- 在这种情况下,内部声明屏蔽了外部同名的声明,让外部的声明的名字无法被访问
1 | func f() {} |
- 特别注意短变量声明语句的作用域范围
1 | var cwd string |
- 虽然cwd在外部已经声明过,但是
:=语句还是将cwd和err重新声明为新的局部变量。 - 因为内部声明的cwd将屏蔽外部的声明,因此上面的代码并不会正确更新包级声明的cwd变量。
1 | var cwd string |
全局的cwd变量依然是没有被正确初始化的,而且看似正常的日志输出更是让这个BUG更加隐晦。