深度学习--6
模型选择
训练误差和泛化误差
训练误差
- 模型在训练数据上的误差
泛化误差
- 模型在新数据上的误差

几个倾向于影响模型泛化的因素
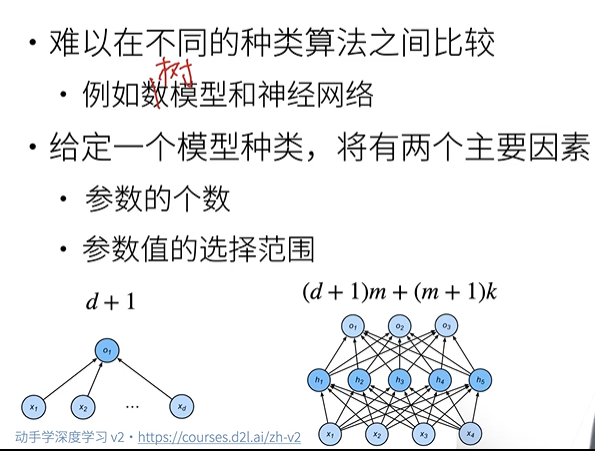
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使你的模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
验证数据集和测试数据集
验证数据集
- 一个用来评估模型好坏的数据集
- 例如拿出50%的训练数据
- 不要跟训练数据混在一起(常犯错误)
测试数据集
- 只用一次的数据集
- 例子
- 未来的考试
- 出价的房子的实际成交价
- 用在Kaggle私有排行榜的数据集
K-则交叉验证
- 没有足够多的数据时使用
- 算法:
- 将训练数据分割成K块
- For i = 1, ... , K
- 使用第i块作为验证数据集,其余的作为训练数据集
- 报告K个验证集误差的平均
- 常用: K = 5或10
过拟合和欠拟合

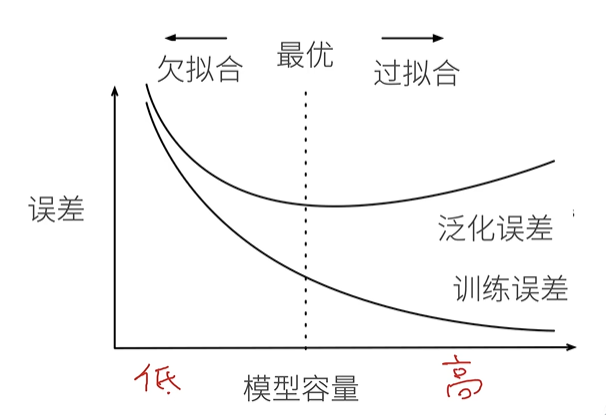
模型容量
- 拟合各种函数的能力
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记住所有的训练数据
模型容量的影响
估计模型容量
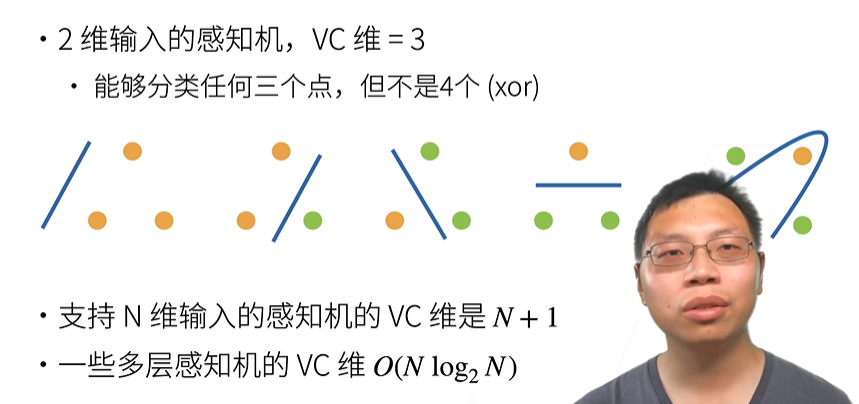
VC维

线性分类器的VC维
VC维的用处

数据复杂度

总结

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yeの博客!