Transformer
seq2seq
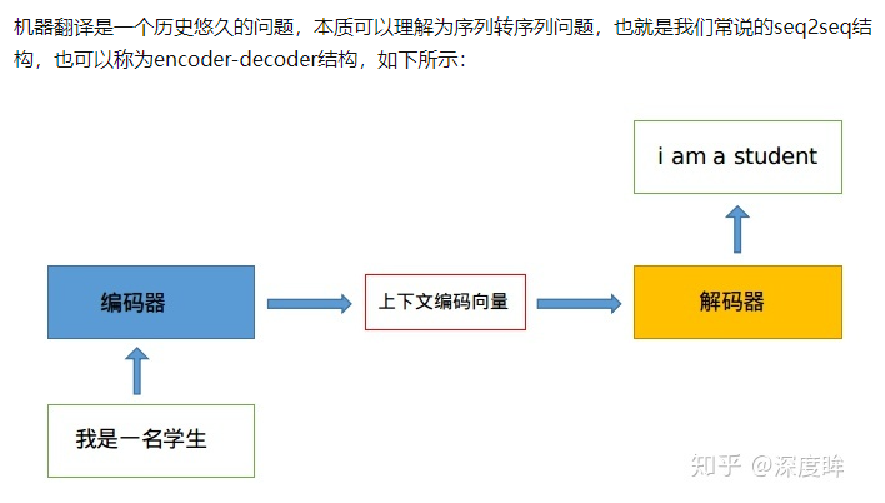

基于attention的seq2seq
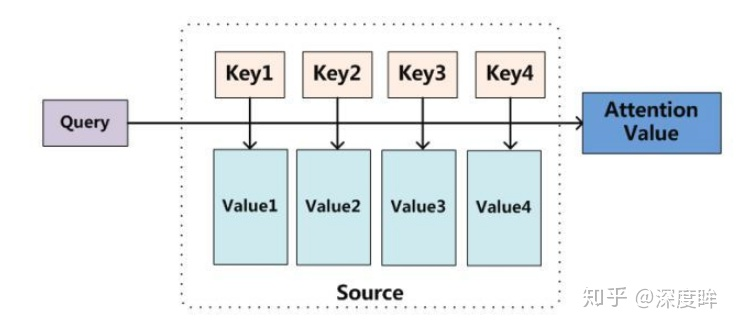



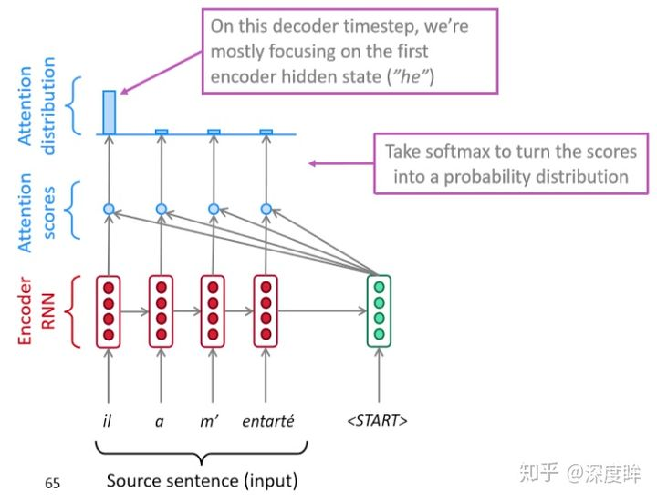
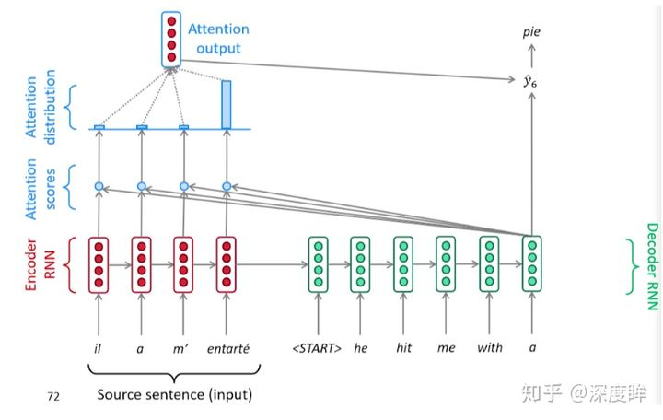
可视化过程


基于transformer的seq2seq
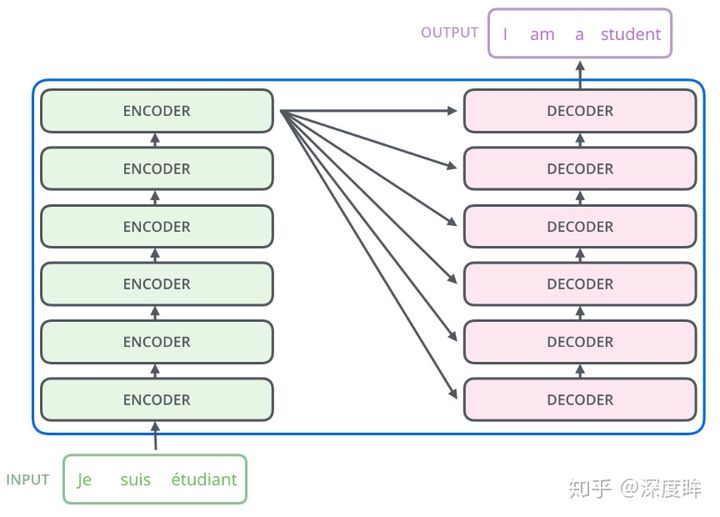

结构
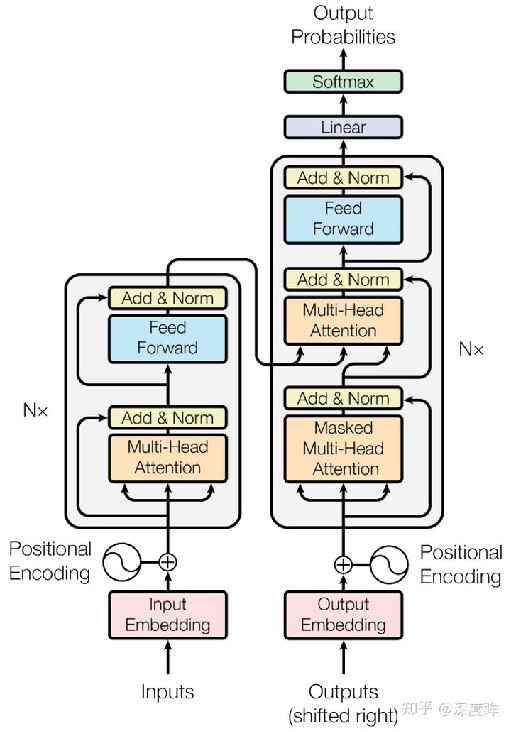
深入分析
流程:编码器输入数据处理->编码器运行->解码器输入数据处理->解码器运行->分类head
编码器输入数据处理
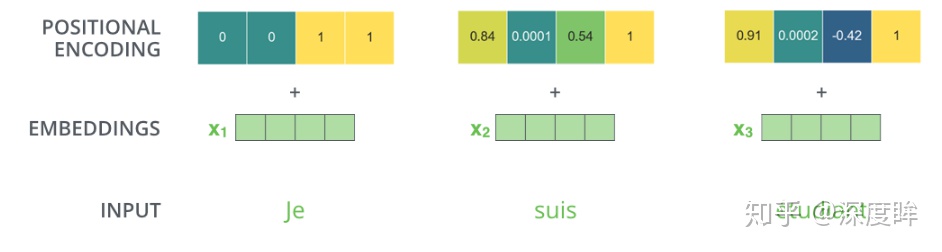
单词嵌入:用向量来标记单词
位置编码(positional encoding)
transfromer内部没有rnn,没有捕捉顺序序列的能力
编码词向量时引入了位置编码position encoding向量来表示两个单词i和j之间的距离
- 即在词向量中加入了单词的位置信息
方法:
网络自动学习:
1
self.pos_embedding = nn.Parameter(torch.randn(1, N, 512))
定义一个超参数,形状与输入嵌入一致,进行相加
自己定义规则
Attention is all you need 中采用了sin-cos规则,具体做法是
- 将向量(N,512)采用如下函数进行处理
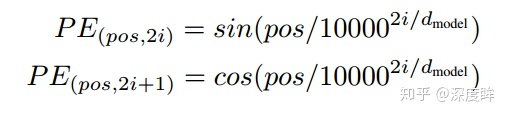
- pos即0~N,i是0-511
- 将一个词向量中的512维度切分为奇数行(cos函数)和偶数行(sin函数)
- 按照原始行号进行拼接
代码:
1
2
3
4
5
6
7
8
9
10
11def get_position_angle_vec(position):
# hid_j是0-511,d_hid是512,position表示单词位置0~N-1
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid)
for hid_j in range(d_hid)]
# 每个单词位置0~N-1都可以编码得到512长度的向量
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
# 偶数列进行sin
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
# 奇数列进行cos
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1可视化

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yeの博客!