计网L10
内容
- Hierarchical routing
- Broadcast routing
- Multicast routing
- Mobile routing
- Adhoc routing
- P2P
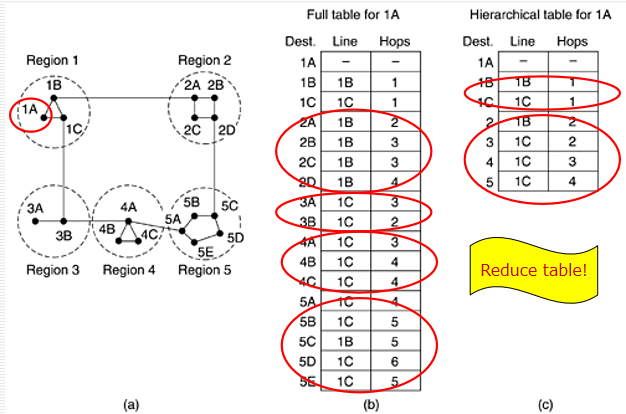
Hierarchical Routing
Broadcast Routing
- 可能的应用:
- 分发天气报告、股票市场更新、现场广播节目。
- 广播路由可以通过以下五种方式之一完成:
- 通过向每个目的地发送唯一的数据包来广播每个数据包。
- 用数据包flood网络,以便每台机器都能接收到它。
- 使用多目的地路由(multi-destination routing)将数据包发送到网络上的特定机器。
- 使用sink tree(或spanning tree)来引导数据包
- 使用反向路径转发(reverse path forwarding)来帮助控制“flood”。
Reverse path forwarding
基本思想:当广播数据包从通常用于发送数据包到广播源的线路到达路由器时,它被转发到除它到达的那条线路之外的所有线路上。 否则,它被丢弃。
Internet Multicasting 组播
源主机给网络中的一部分目标用户发送数据包
IP 支持多播,使用 D 类地址。
每个 D 类地址标识一组主机。
- 28位可用于识别组,因此支持2.5亿组。
IP multicast很重要:
- Member management(IGMP/MLD)路由器获悉该网段的组播组成员
- Multicast routing table(PIM-DM/SM)
组播是由特殊的组播路由器实现的。
- 应用层组播
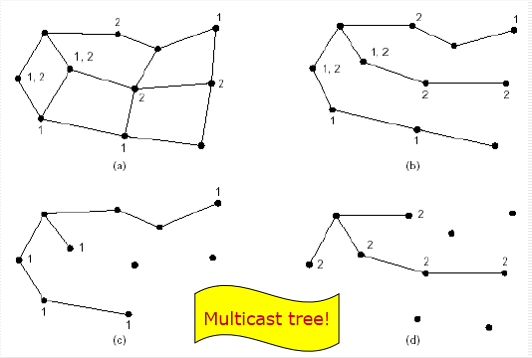
Multicast routing
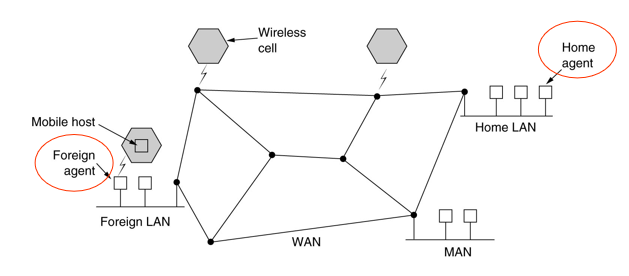
Routing for Mobile Hosts
什么是移动主机? 我们包括:
- 物理连接到网络的迁移主机,但会四处移动(我们的笔记本电脑,固定的)。
- 漫游主机实际上在运行中计算并希望在它四处移动时保持其连接
所有主机都有一个永久的host location和一个永久的home address,可用于确定他们的家庭位置。
具有移动用户的系统中的路由目标是使使用他们的家庭地址向移动用户发送数据包成为可能,并使数据包无论他们身在何处都能有效地到达他们。
世界被分成小区域
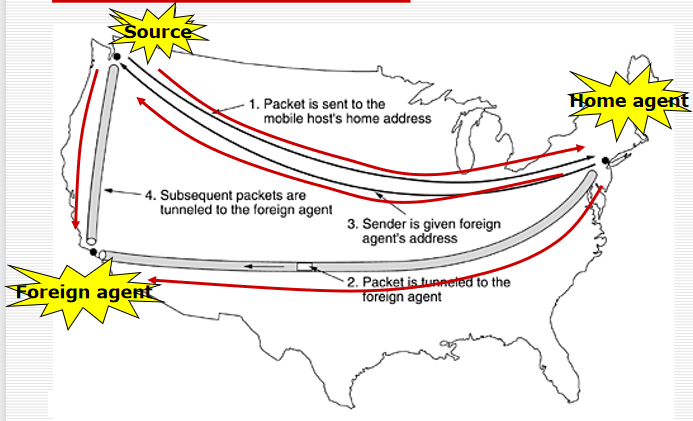
- 每个区域都有一个或多个foreign agents(外地代理),负责跟踪所有访问该区域的移动用户。
- 每个区域也有一个home agent(家乡代理),它会跟踪住家在该区域但当前正在访问另一个区域的用户。
Mobile Host Registration Procedure
- 每个外地代理定期广播一个数据包,宣布它的存在和地址。
- 移动主机向外地代理注册,给出其家乡地址、当前数据链路层地址和一些安全信息。
- 外地代理联系移动主机的家乡代理,通知用户当前在外地区域。
- 家乡代理检查外地代理提供的安全信息,如果信息正确,则通知外地代理继续。
- 当外地代理得到家乡代理的确认时,它在其表中创建一个条目并通知移动主机它现在已注册。
- 当用户离开一个区域时,它应该注销自己。
Packet Routing For Mobile Hosts (tunnel)
移动主机的数据包路由(隧道)
Routing in Ad Hoc Networks -- Ad Hoc 网络中的路由
- Ad hoc 网络(或 MANET,Mobile Ad hoc
NETworks)涉及主机和路由器都是移动的:
- 战场上的军车 - 没有基础设施
- 海上的舰队 - 一直在移动
- 地震应急工程 - 基础设施被毁。
- 一群拿着笔记本电脑的人 - 在一个缺乏 802.11 的地区。
- 对于自组织网络,拓扑可能一直在变化,自组织网络中的路由与其固定对应网络中的路由完全不同。
Peer-to-Peer Networks
点对点(或 P2P)计算机网络是一种主要依赖网络中参与者的计算能力和带宽而不是将其集中在数量相对较少的服务器上的网络。
所有节点都是对称(symmetric)的,没有中央控制或层次结构。
没有人愿意托管和维护一个中心化的数据库,甚至一个中心化的索引。
点对点网络的优势
- 所有客户端都提供资源,包括带宽、存储空间和计算能力。
- 点对点网络的分布式特性也提高了纯 P2P 系统出现故障时的鲁棒性
非结构化和结构化 P2P 网络
- 非结构化P2P网络
- 为了在网络中找到所需的数据,必须通过网络泛洪查询,以便找到尽可能多的共享数据的对等点。
- 大多数流行的 P2P 网络,如 Napster、Gnutella 和 KaZaA,都是非结构化的。
- 结构化 P2P 网络
- 维护分布式哈希表 (DHT) 并允许每个对等方负责网络中内容的特定部分。
- 一些著名的结构化 P2P 网络是 Chord、Pastry、Tapestry、CAN 和 Tulip
- 非结构化P2P网络
P2P: centralized directory
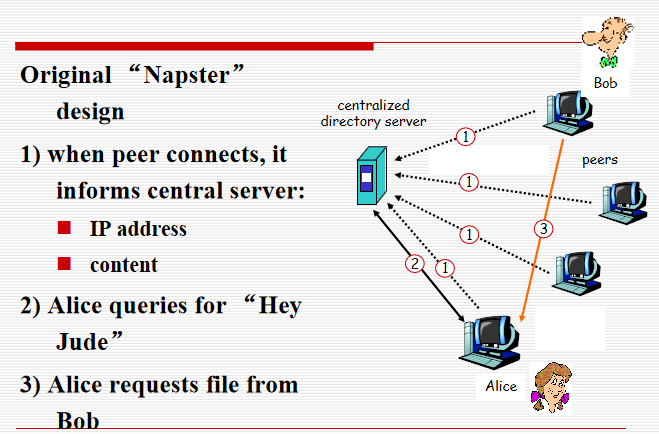
P2P: problems with centralized directory
- Single point of failure 单点故障
- Performance bottleneck 性能瓶颈
- Copyright infringement 侵犯版权
Gnutella:protocol

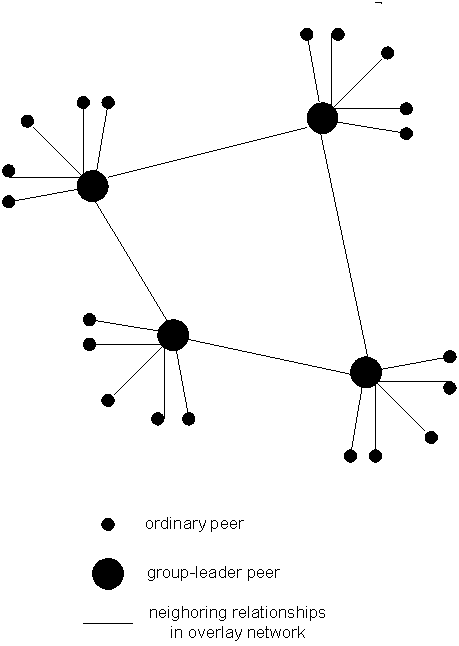
利用异质性:KaZaA
- 每个对等点要么是group leader,要么是指派给一个group leader。
- peer 与其 group leader之间的 TCP 连接。
- 一些group leader对之间的 TCP 连接。
- group leader跟踪其所有子项中的内容。
KaZaA: Querying
每个文件都有一个哈希值和一个描述符
客户端向其group leader发送关键字查询
group leader回应匹配:
- 对于每个匹配项:元数据、哈希、IP 地址
如果group leader将查询转发给其他group leader,他们会回复匹配项
客户端然后选择要下载的文件
- 使用哈希作为标识符的 HTTP 请求发送给持有所需文件的对等方
Node Lookup in Chord -- Chord 中的节点查找
Chord 系统由 n 个参与用户组成。
每个用户节点都有一个 IP 地址,可以使用哈希函数将其哈希为 m 位数字。
- Chord 使用 SHA-1 进行哈希处理。
- 任何 IP 地址都会转换为 160 位数字,称为节点标识符。
从概念上讲,所有$ 2^{160} $个节点标识符都按升序排列在一个大圆圈中。
其中一些对应于参与节点,但大多数不对应。
将函数successor(k) 定义为顺时针方向跟随k 的第一个实际节点的节点标识符。
记录的名称也用散列(即 SHA-1)散列以生成一个 160 位的数字,称为密钥。
- key = hash(name)
为了向其他人提供记录,节点构建一个由 (name, my-IP-address) 组成的元组,然后要求successor(hash(name)) 存储该元组。
这样,索引随机分布在节点上。
对于容错,可以使用 p 个不同的哈希函数将每个元组存储在 p 个节点上。
如果某个用户稍后想要查找名称,他会对其进行哈希处理以获取密钥,然后使用 successor (key)查找存储其索引元组的节点的 IP 地址。
查找程序:
- 请求节点向其后继节点发送一个包含其 IP 地址和它正在寻找的密钥的数据包。
- 数据包在环上传播,直到它定位到正在寻找的节点标识符的后继者。
- 该节点检查它是否有任何与密钥匹配的信息,如果有,则将其直接返回给请求节点。
作为第一个优化,每个节点都可以保存其后继节点和前驱节点的 IP 地址,以便可以顺时针或逆时针发送查询。
在大型对等系统中,线性搜索所有节点的效率非常低,因为每次搜索所需的平均节点数为 n/2。
为了大大加快搜索速度,每个节点还维护 Chord 所谓的 finger table(指取表)。
- finger table有 m 个条目,从 0 到 m - 1 索引,每个条目指向一个不同的实际节点。
- 每个条目都有两个字段:开始和后继者的 IP 地址(开始)
- 节点 k 处条目 i 的字段值是:
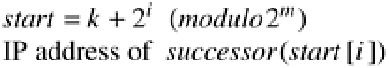
- 使用finger table,在节点k 处查找key 的过程如下。
- 如果key介于k和successor(k)之间,那么保存key信息的节点就是successor(k),搜索结束。
- 否则,搜索finger 表以找到其起始字段是key 的最接近前驱的条目。 然后将请求直接发送到该指纹表条目中的 IP 地址,要求它继续搜索。
- 平均查找次数为 \(log_2n\)。
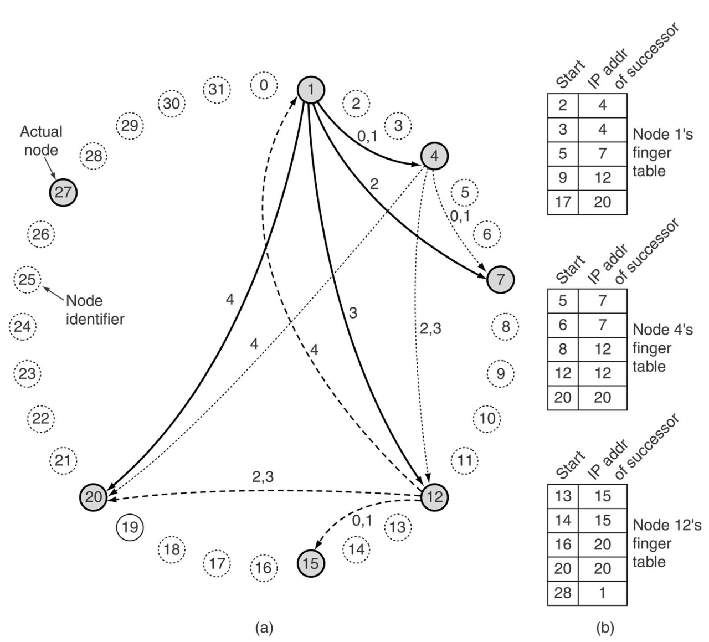
Lookup key= 3 on node 1 Lookup key=14 on node 1 Lookup key=16 on node 1
New Node Join And Leave
- 当一个新节点 r 想要加入时,它必须联系某个现有节点并要求它为它查找后继节点 (r) 的 IP 地址。
- 然后新节点向后继节点 (r) 询问其前驱节点。
- 然后,新节点要求这两个节点在圆圈中的它们之间插入 r。
- 当一个节点优雅地离开时,它把它的密钥交给它的后继,并通知它的前任它的离开,这样前任就可以链接到离开节点的后继。
- 为了缓解节点崩溃带来的问题,每个节点不仅要跟踪它的直接后继,还要跟踪它的直接后继
Congestion 拥塞
拥塞是子网(部分)中存在太多数据包,性能急剧下降的情况
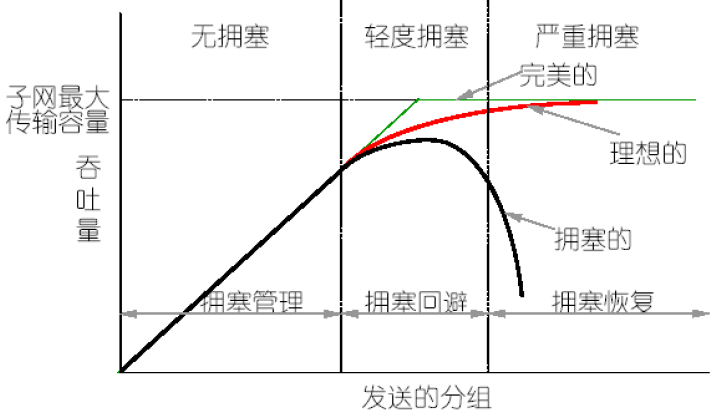
Factors Causing Congestion 造成拥塞的因素
- 输入流量速率超过输出线路的容量。
- 例如 多条输入线被转发到同一条输出线。
- 添加更多内存可能会有所帮助。
- 无限的内存怎么样?
- 路由器中的处理器太慢而无法执行簿记任务(排队缓冲区、更新表等)。
- 线路容量和处理器能力需要平衡。
Congestion Control vs. Flow Control 拥塞控制与流量控制
- 拥塞控制 Congestion Control
- 它确保子网能够承载提供的流量。
- 这是一个全局问题,涉及所有主机、所有路由器的行为、路由器内的存储和转发处理等。
- 流量控制 Flow Control
- 它涉及给定发送方和给定接收方之间的点对点流量。
- 它确保快速发送方不能以比接收方能够吸收数据的速度持续传输数据。
- 主机可能会收到“减速”消息,因为接收器无法处理负载或因为网络无法处理它(confused)。
Congestion Metrics 拥塞度量
- 由于缓冲区空间不足而丢弃的所有数据包的百分比
- 平均队列长度
- 超时并重新传输的数据包数
- 平均数据包延迟
- 数据包延迟的标准偏差
- 不断上升的数字表明日益拥挤。
Congestion Information Propagation 拥塞信息传播
- 检测到拥塞的路由器向流量源发送一个单独的警告数据包。
- 每个数据包中可以保留一个位或字段。 当路由器检测到拥塞状态时,它会在所有传出数据包中填充该字段以警告邻居。
- 主机或路由器定期发送探测数据包以明确询问拥塞情况并在问题区域周围路由流量
Congestion Control In Virt.-circuit Subnets 虚拟电路子网中的拥塞控制
- Admission control(准入控制,简单粗暴)
- 一种闭环技术,可以防止已经开始恶化的拥塞。
- 基本思想:一旦发出拥塞信号,就不会再建立虚拟电路,直到问题消失。
- 备用路由(绕过问题区域)
- 允许新的虚拟电路,但在问题区域周围小心地路由所有新的虚拟电路。
- 协商主机和子网之间的协议,以便子网在电路建立时可以预留路径上的资源。(资源预留)
- 交通量和交通形态
- 所需的服务质量
- 其他参数
Congestion Control In Datagram Subnets 数据报子网中的拥塞控制
- 每个路由器都可以监控其输出线路和其他资源的利用率。
- 每行都与一个变量 u 相关联,其值 (0.0 -1.0) 反映了最近的利用率。
- 每当 u 移动到阈值以上时,输出线就会进入警告状态。
- 检查每个新到达的数据包以查看其输出线是否处于警告状态。
Actions When In Warning State
- The Warning Bit(警告位)

- 在数据包的报头中设置了一个特殊位。
- 该位被复制到下一个发送回源的确认中。
- 源监视设置了位的确认部分并相应地调整其传输速率。
- Choke Packets(极限极限)
- 路由器将阻塞数据包发送回源主机,将数据包中的目的地提供给它。
- 当源主机收到choke包时,需要将到达目的地的流量减少一定的百分比。
- 主机应在固定时间间隔内忽略指向同一目的地的阻塞数据包
- 如果在侦听期间没有阻塞数据包到达,主机可能会再次增加流量。
- Hop-by-Hop Choke Packets(逐跳抑制演奏)
- 在高速或长距离下,向源主机发送阻塞数据包效果不佳,因为反应太慢。
- 另一种方法是让扼流数据包在它经过的每一跳都生效。
- 这种逐跳方案的净效果是以消耗更多上游缓冲区为代价在拥塞点提供快速缓解。
Fragmentation
每个网络都对其数据包施加了一些最大尺寸。
- 硬件(例如,TDM 传输时隙的宽度)
- 操作系统(例如,所有缓冲区都是 512 字节)
- 协议(例如,数据包长度字段中的位数)
- 符合一些(国际)国家标准
- 希望将错误引起的重传减少到一定程度
- 希望防止一个数据包占用信道时间过长
网络设计者不能自由选择他们希望的任何最大数据包大小。
最大有效载荷范围从 48 字节(ATM 信元)到 65,515 字节(IP 数据包),尽管较高层的有效载荷大小通常更大。
如果一个网络只允许 48 字节的数据包,而另一个网络允许 65515 字节的数据包,那么很难通过只允许较小数据包的网络获取大数据包。
如何才能做到这一点? – Fragmentation(分段)
- Fragmentation是将数据包分解成几个较小的数据包以通过网络发送的过程。
- 问题不在于分解数据包以发送它,而是在另一端将数据包重新组合在一起。
- 有两种不同类型的碎片——透明(transparent)和非透明(non-transparent)。
透明分段试图通过在每次离开网络时重构数据包,使分段对路由上的任何其他网络不可见。
不透明的分段会导致所有分段的数据包通过多个网络到达目的地,而让目的地将它们重新组合在一起。
问题
- 透明碎片
- 出口网关必须知道它何时收到了所有的碎片。
- 所有数据包必须通过同一个网关退出。
- 重复重新组装然后重新整理大数据包所需的开销很大。
- 不透明的碎片
- 它要求每个主机都能够进行重组。
- 总开销会增加,因为每个片段都必须有一个标头。
A Method of Numbering the Fragments
- 定义一个小到足以通过每个网络的基本片段大小。
- 当原始数据包被分片时,除了最后一个(较短的)外,所有的碎片都等于基本碎片大小。
- 一个互联网数据包可能包含几个基本片段。
- 互联网数据包头必须提供
- 原始包号
- 互联网数据包中包含的第一个基本片段的编号,以及
- 一位指示互联网数据包中的最后一个基本片段是否是原始数据包的最后一个。
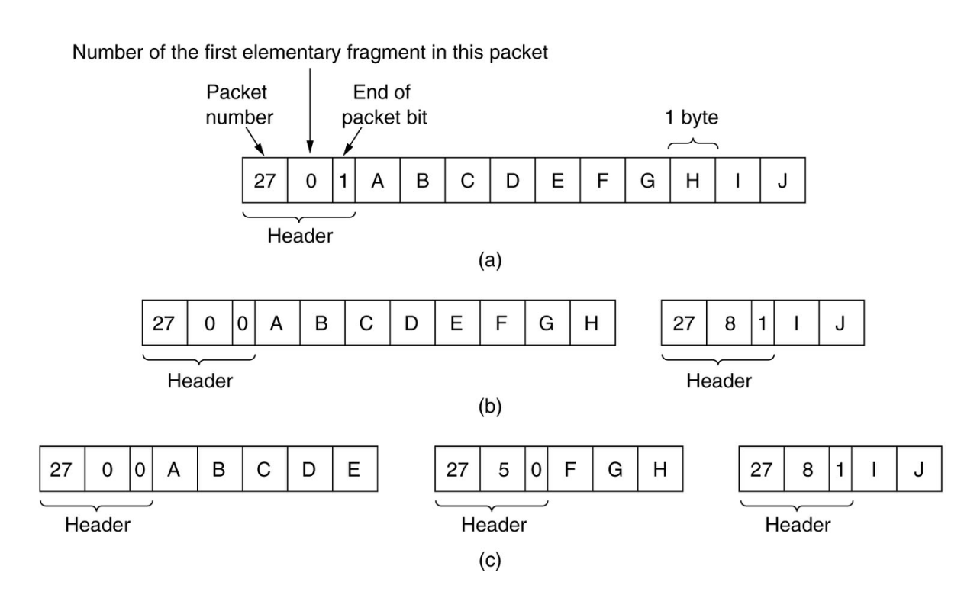
Outline
- Main function of router
- Learn IP
- IP packet format
- IP address and it’s classification
- Reserved IPv4 address
- Subnet and subnetting
Internet and Its Network Layer
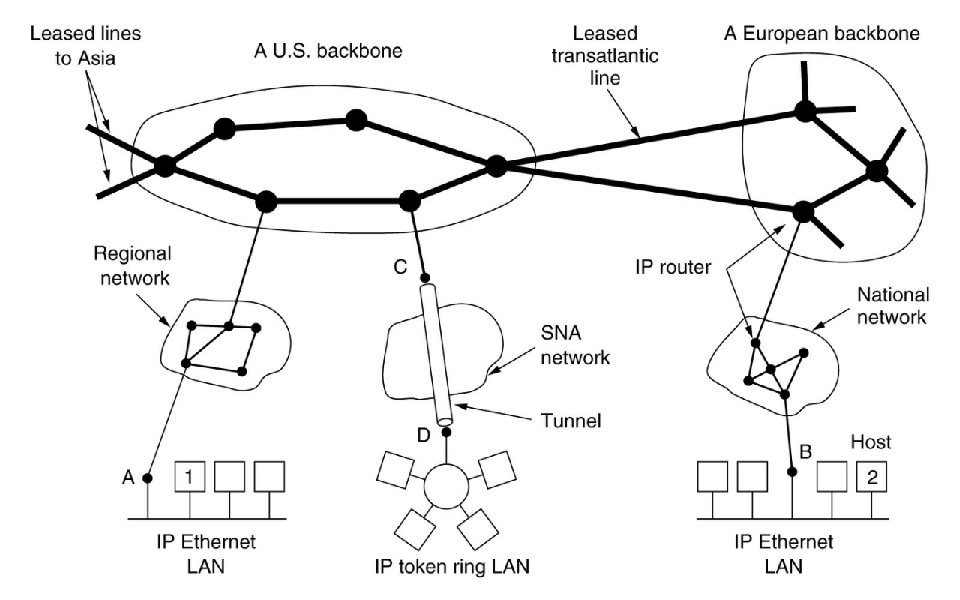
- 可以将 Internet 视为互连的子网或Autonomous Systems (ASes) 的集合。
- 将整个 Internet 连接在一起的粘合剂是网络层协议 IP(Internet 协议)。
- 它的工作是提供一种best-efforts(尽力而为)(即不保证)的方式来将数据报从源传输到目的地。
Internet - Collection of Subnetworks
Addressing(寻址)
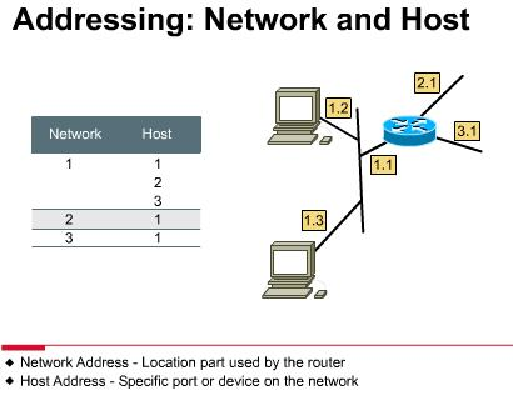
- 寻址:连网的目的是共享资源、与远端节点通信,要做到这一点,首先必须找到目的节点,寻找目的节点(设备)的过程叫做寻址。
- 两类
- MAC寻址:根据MAC地址定位目的地
- IP寻址:根据IP地址定位目的地
IP addressing
- 步骤
- 数据包到达路由器
- 路由器转发数据包
- 定位目的地
- 类比:邮寄
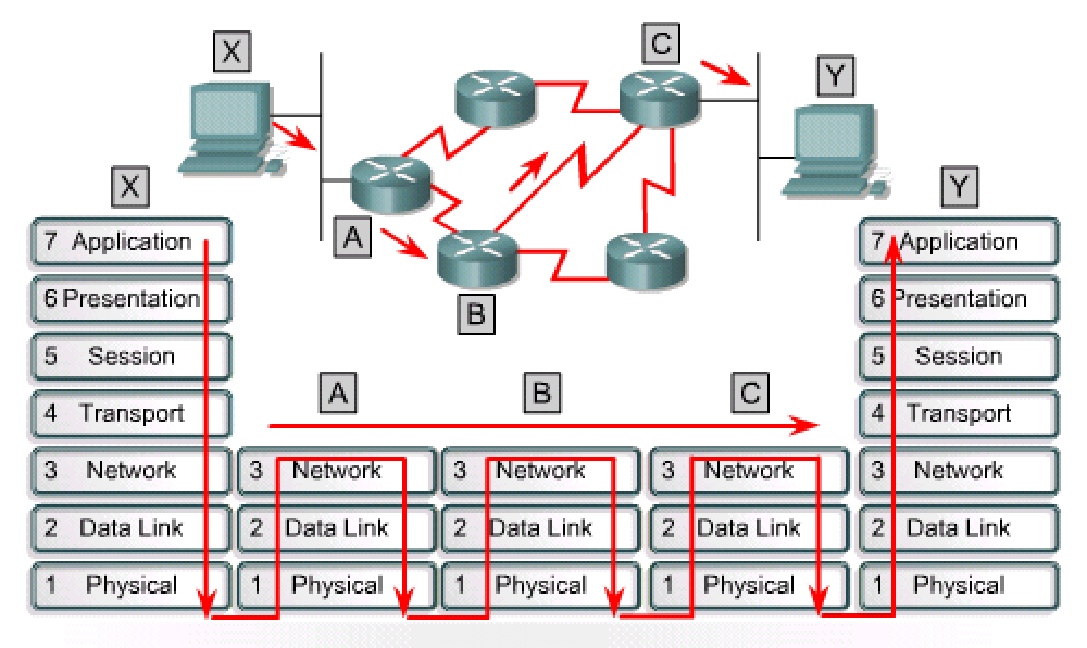
Main function of router
- 路由器进程
- 开包(解封装)
- 确定目标网络
- 查找路由表,重新封装并转发
- 主功能
- 路由
- 向前
- 其他
Routing table
- 包括网络地址、接口、度量(例如跳数)、子网掩码、网关等。
- 除了连接设备的IP和MAC地址外,路由器还有其邻居路由器的IP和MAC地址(arp表)
- 可能有些不同,因为工厂不同
ARP table and routing table
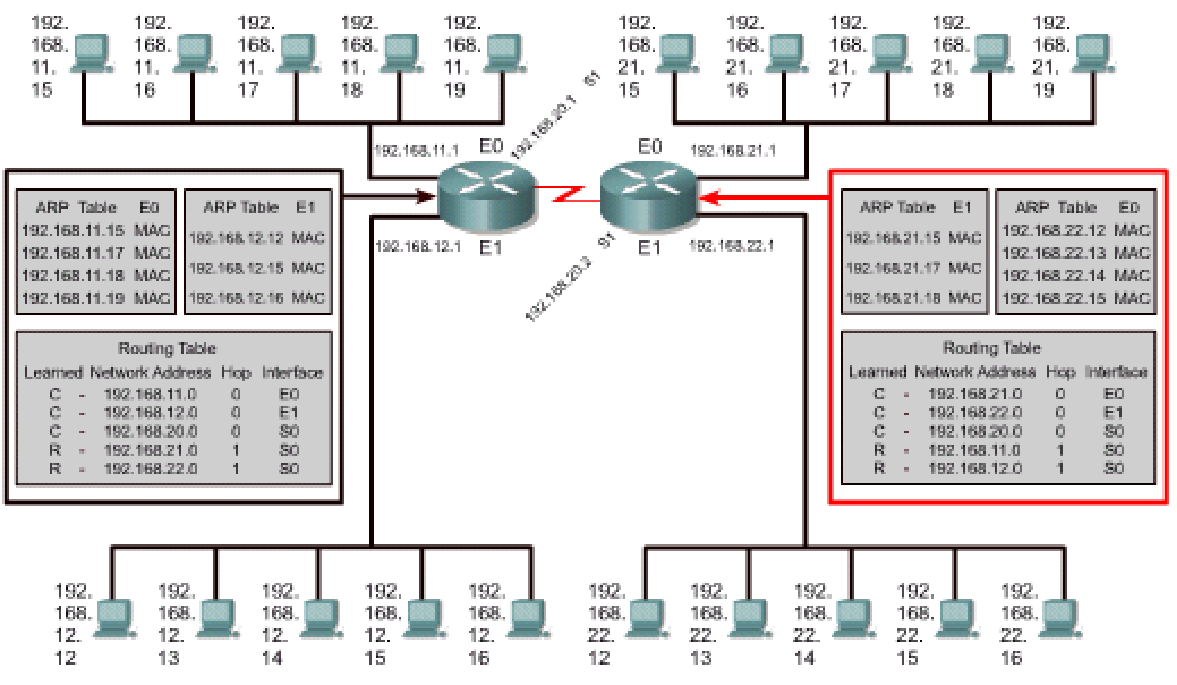
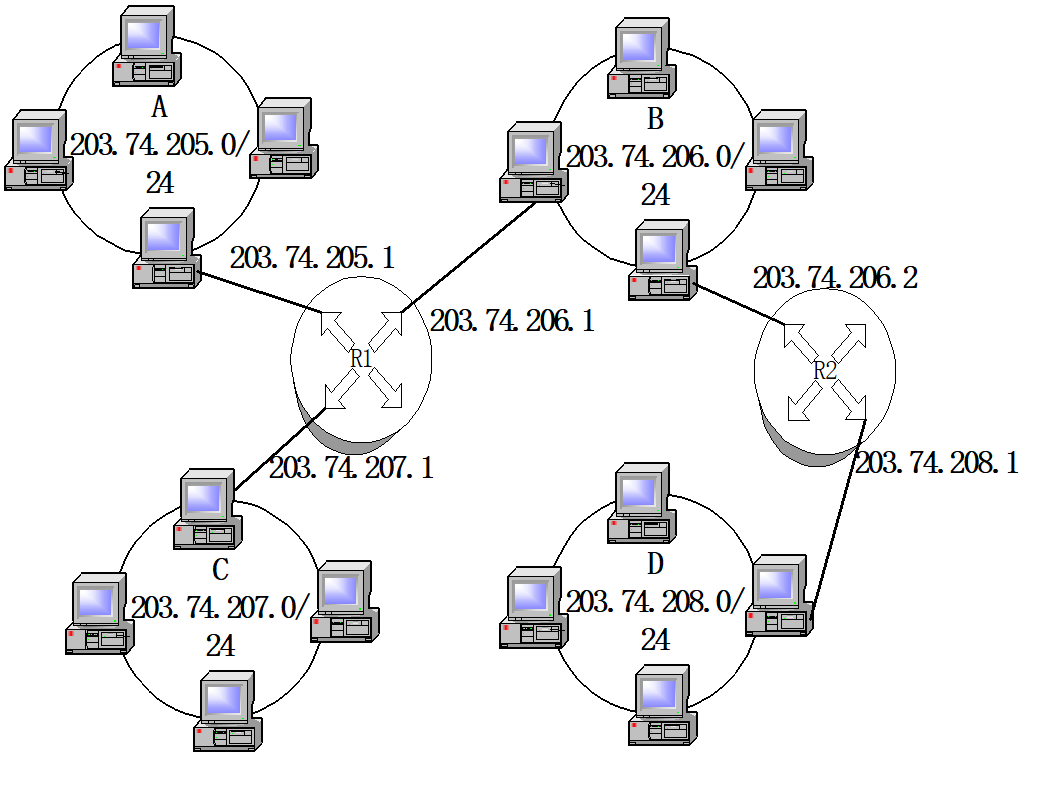
Routing of router R1

Internet protocol
- IP
是提供一种尽力而为(即,不保证)的方式来将数据报(数据包)从源传输到目的地
- 路由协议
- 互联网协议 Internet protocol
- 数据包格式
- 寻址
IP packet format
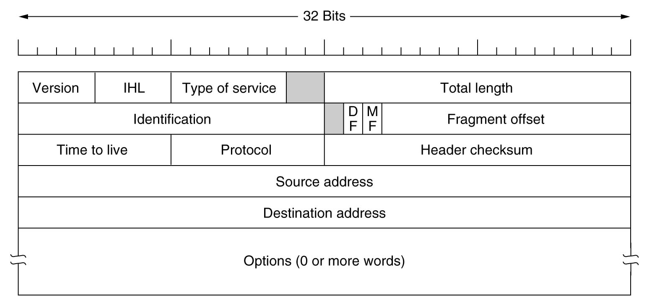
DF: don't fragment
MF: More fragments
IP address
IP地址:网络号和主机号
IP地址的二进制数字

缺点:难以记住
IP地址的点分十进制表示法
- 二进制IP很难记住
- 点分十进制表示法:
- 32 位被分成 4 个 8 位组
- “.” 用于分隔 8 位组
- 每个 8 位组用十进制写,从 0 到 255
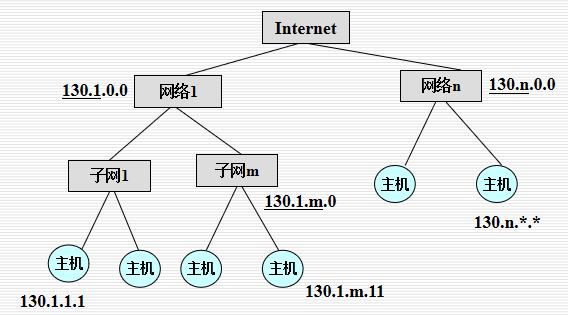
Hierachical property of IP addr.
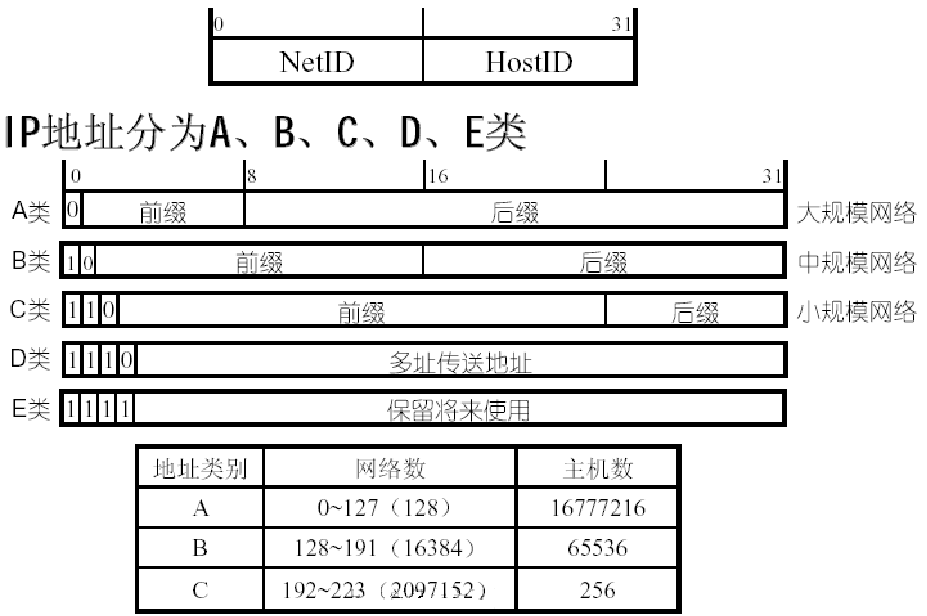
Classification of IP address IP地址的分类
特殊的IP地址
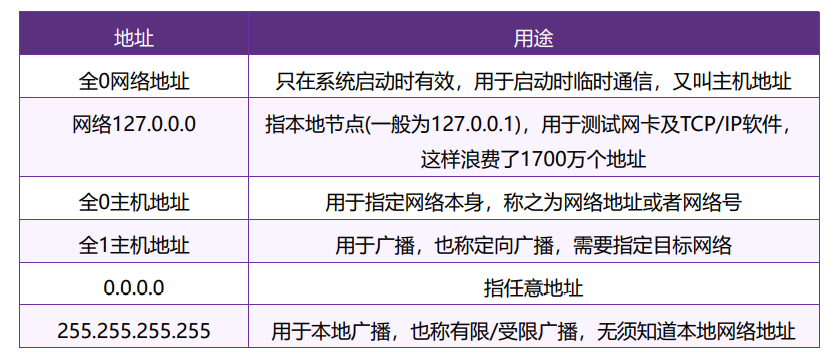
Flood Broadcast = Local Broadcast
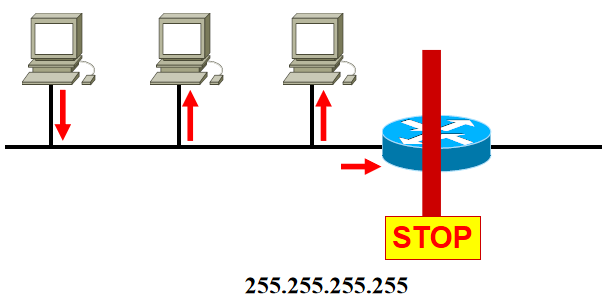
Direct Broadcast
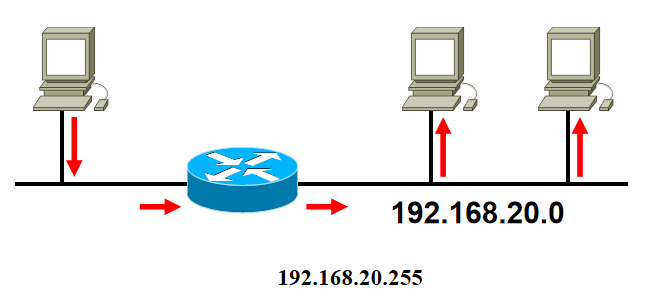

Public and private address
Subnet(子网)
- LAN 可能会变得太大而无法处理,必须拆分为多个子网。
- 子集允许将网络分成几个部分供内部使用,但对于外部世界仍然像单个网络(即单个路由表条目)一样。
- 这允许在组织内连接不同的子网。
Main router的作用
- 与外界的交流
- 主路由器转发来自外部的数据包,但如何知道内部网络结构?
- 一张桌子?
- 一种机制,子网掩码
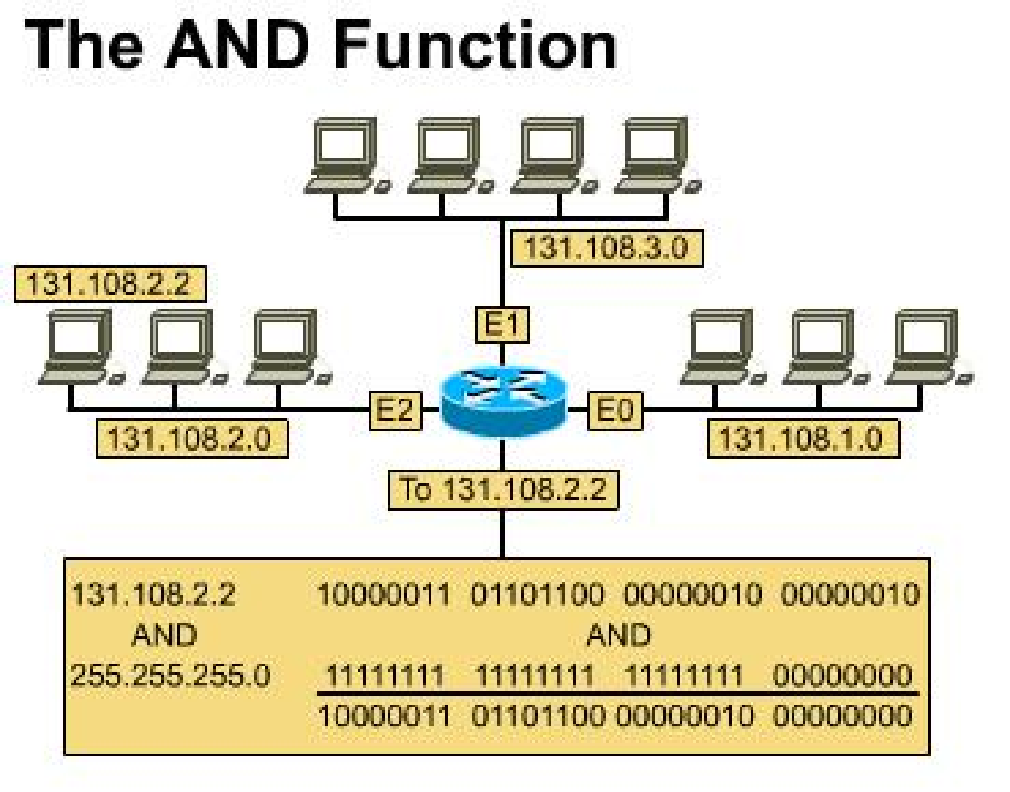
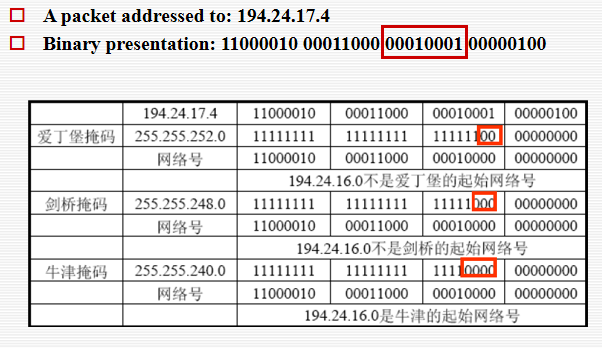
Subnet Masks 子网掩码
- 路由器使用掩码来确定数据包应该传送到哪个子网。
- 子网掩码可以用点分十进制表示法指定,添加一个斜杠,后跟网络 +
子网部分的位数。
- 255.255.255.224
- 202.10.23.102/27
- 路由器将目的地址与子网掩码进行 AND 运算,以获得数据包应该去的路由器的地址。
- 使用这种方法减少了每个路由器必须存储的单个地址的数量,从而产生更小的路由器表。
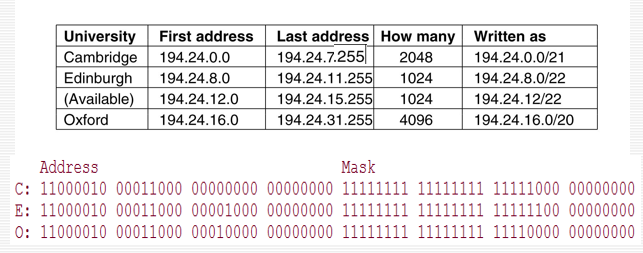
Addr. Of subnet
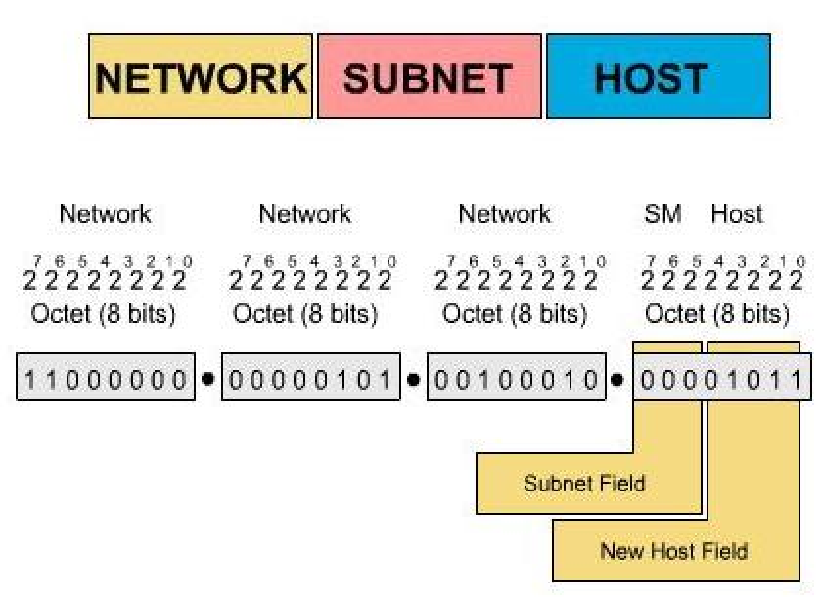
子网是通过从 IP 地址的主机部分借用位来构建的
子网划分导致 IP 地址空间丢失
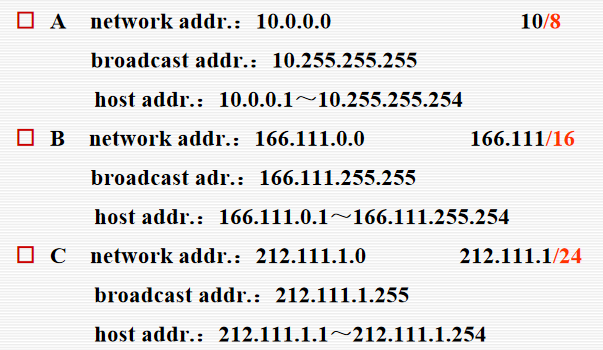
- 例如:C类IP 202.38.197.0,256个IP地址,254个有效IP。
- 4个子网,IP地址总数,2*62=124。
子网划分:将大网络划分为小子网
借用规则
Outline
- The basic idea of CIDR
- The principle of NAT/PAT
- ICMP and it’s application
- Principle Address resolution protocol
- ARP
- RARP
- Learn assignment of IP address (RARP)
IP address problem
- IP 正迅速成为其流行的受害者:它的地址已用完。
- 原则上,存在超过 40 亿个地址,但按类组织地址空间的做法浪费了数百万个。
- 对于大多数组织:
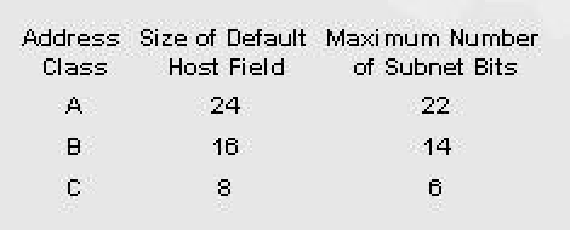
- A类网络,16M地址太大了
- C类网络,256个地址太小了
- 具有 65,536 个地址的 B 类网络似乎恰到好处(许多组织要求使用 B 网络)。
- 实际上,所有 B 类网络中有一半以上的主机少于 50 台!
- 如何提供更多(和更小)的 B 类地址? 或者 C 类网络使用 10 位而不是 8 位作为主机号?
- 路由表爆炸
CIDR –Classless InterDomain Routing 无类别域间路由
- 路由表问题的解决方法和addr。 问题是 CIDR。
- RFC 1519 中描述了 CIDR 背后的基本思想。
- 以可变大小的块分配 IP 地址,而不是根据类别分配 IP 地址。
- 例如 需要2000个地址
- 以可变大小的块分配 IP 地址,而不是根据类别分配 IP 地址。
- CIDR 可以使用前缀 13~27。
Routing With CIDR
- 每个路由表条目都通过提供 32 位掩码进行扩展。
- 每个路由表由一组(IP 地址、子网掩码、出线) 三元组组成。
- (IP address, subnet mask, outgoing line)
- 当一个数据包进来时,
- 首先提取其目标 IP 地址。
- 屏蔽目标地址并将其与查找匹配项的表条目进行比较。
- 如果多个条目(具有不同子网掩码长度)匹配,则使用最长的掩码。


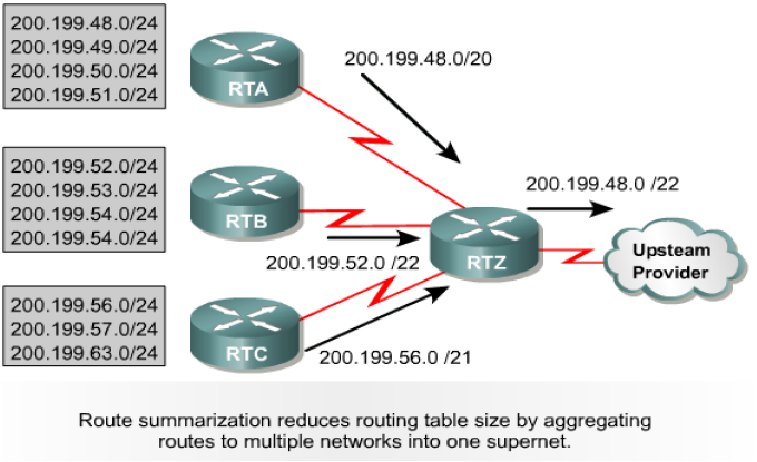
Routing cluster(路由聚合)
- Reduce routing table
- Separate up-down(隔离路由翻动)

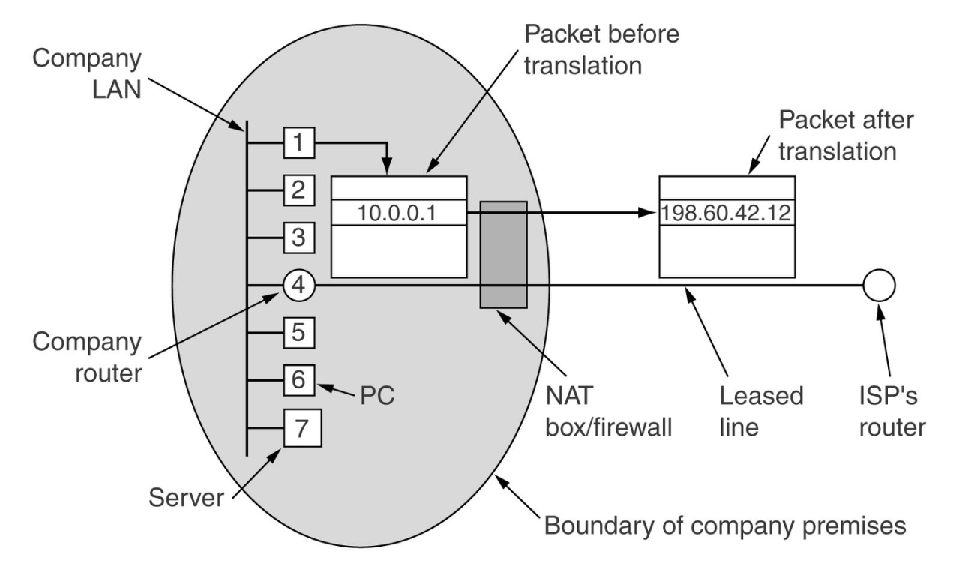
NAT outline
- NAT:网络地址转换NAT
- 私人IP地址(私人地址)与全球IP地址(公有地址)之间的转换
- PAT:端口地址转换
- 映射许多 IP 地址。 到一个 IP 地址。 不同的端口
- 私有IP地址:非路由地址。

- 需要快速修复来解决 IP 地址用完的问题。
- NAT(网络地址转换)在 RFC 3022 中有描述。
- 该过程涉及使用私有内部 IP 地址,然后在离开 LAN 时将这些 IP 地址转换为有效的 IP 地址。
- 此转换由 NAT 盒完成。 NAT 盒能够通过使用大型转换表来转换和跟踪地址。
- 当传入的数据包到达 NAT 盒时,它会查找源端口字段,该字段用作 NAT 表中内部 IP 地址的索引。
NAT Operation
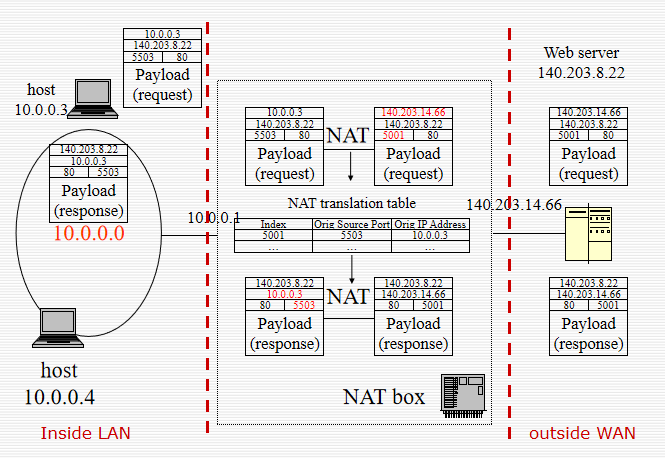
NAT Issues
NAT 违反了 IP 的架构模型——每个 IP 地址在全球范围内唯一标识一台机器。
它把互联网变成了一个“面向连接”的网络。 NAT 盒维护连接的状态,如果它崩溃,链接也会崩溃。
协议层 k 假设协议层 k+1 已放入有效载荷中,从而违反了层独立性。
如果使用 TCP 或 UDP 以外的某些协议,NAT 可能会失败。
如果 IP 地址被插入到有效载荷数据(即消息文本)中,那么 NAT 表将不会转换该信息,并且可能会出现问题。
一台NAT机器的限制是61,440(65536-4096)台机器。
Internet network-layer protocol
- 除了互联网协议,还有一些其他的附属协议
- ICMP
- ARP
- RARP
- 引导程序
- DHCP
ICMP - Internet Control Message Protocol
用于报告意外事件(错误)或测试互联网。 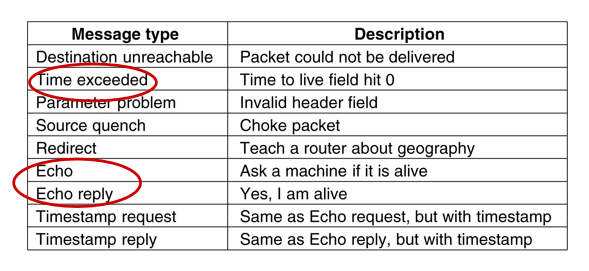
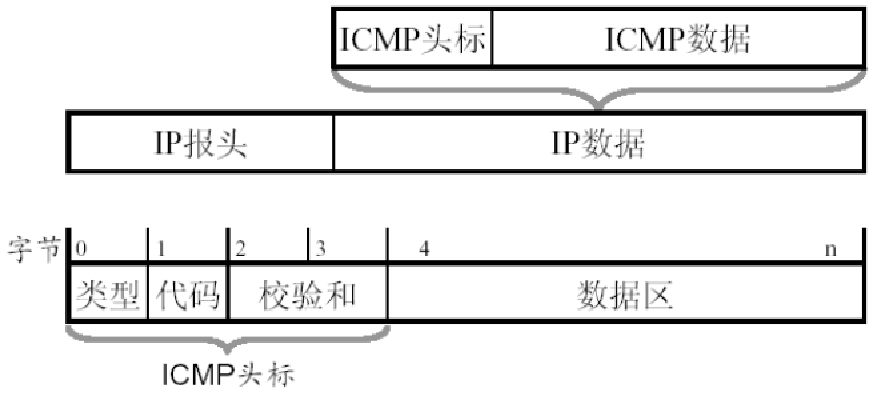
ICMP message format
Address mapping ( 地址映射)
- ARP (地址解析协议):
- Address Resolution Protocol 地址解析协议
- IP addr. -> MAC addr.
- ARP 解决了找出哪个物理地址对应于给定 IP 地址的问题。
- ARP 在 RFC 826 中定义。
- RARP (逆向地址解析协议)
- Reserve Address Resolution Protocol
- MAC addr. -> IP addr.
Assignment way of IP addr.
- 静态赋值
- 动态分配
- 给定一个以太网地址,对应的 IP 地址是什么?
- RARP(反向地址解析协议)在RFC 903中定义。它使用全1(有限广播)的目的地址到达RARP服务器,RARP服务器发回相应的IP地址。
- BOOTP 在 RFC 951、1048 和 1084 中定义。它使用通过路由器转发的 UDP 消息。 它可以提供更多信息。 (缺点 :手动配置)
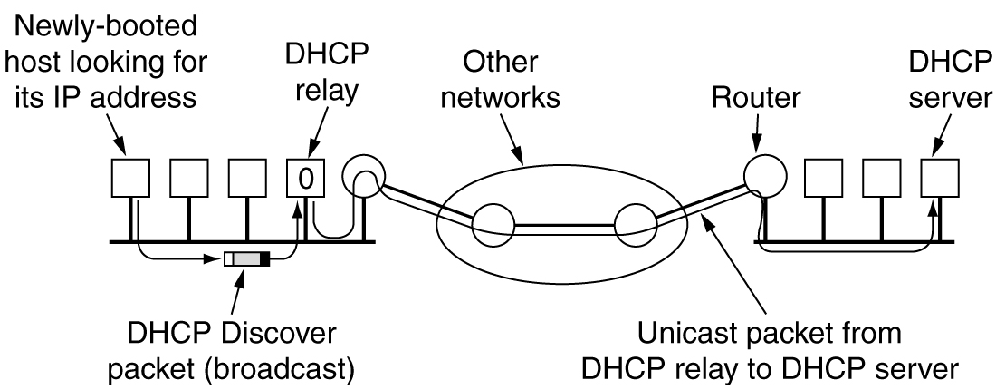
- DHCP(动态主机配置协议)在 RFC 2131 和 2132 中有描述。 RARP
- 给定一个以太网地址,对应的 IP 地址是什么?
DHCP:动态主机配置协议
Dynamic host configure protocol 可以灵活分配IP地址,节约IP地址的使用