深度学习-9
层和块
单个神经元:
- 接受一些输入
- 生成相应的标量输出
- 具有一组相关参数
- 参数可以更新以优化某些感兴趣的目标函数
层:
- 接受一组输入
- 生成相应的输出
- 由一组可调整参数描述
使用softmax回归时,一个单层本身就是模型
块:
- 块可以描述单个层、由多个层组成的组件或整个模型本身。
- 使用块进行抽象的一个好处是可以将一些块组合成更大的组件,这一过程通常是递归的
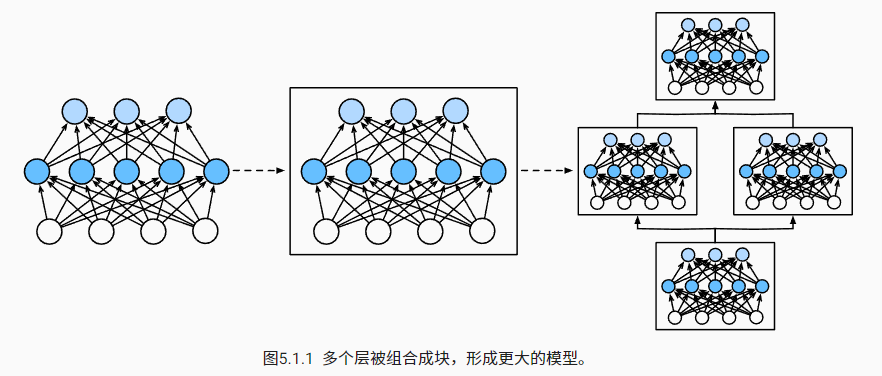
块由类表示
- 它的任何子类都必须定义一个将其输入转换为输出的正向传播函数,并且必须存储任何必需的参数。
- 注意,有些块不需要任何参数。
- 最后,为了计算梯度,块必须具有反向传播函数。
- 自动微分有一些后端实现,只需要考虑正向传播函数和必需的参数。
多层感知机
1 | import torch |
- nn.Sequential()定义了一个特殊的Module,即在PyTorch中表示一个块的类。
- 两个全连接层都是
Linear类的实例,Linear类本身就是Module的子类。 - 正向传播(
forward)函数也非常简单:它将列表中的每个块连接在一起,将每个块的输出作为下一个块的输入。
自定义块
块的基本功能:
- 将输入数据作为其正向传播函数的参数。
- 通过正向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面模型中的第一个全连接的层接收任意维的输入,但是返回一个维度256的输出。
- 计算其输出关于输入的梯度,可通过其反向传播函数进行访问。通常这是自动发生的。
- 存储和访问正向传播计算所需的参数。
- 根据需要初始化模型参数。
1 | class MLP(nn.Module): |
顺序块--Sequential
两个关键函数:
- 一种将块逐个追加到列表中的函数
- 一种正向传播函数,用于将输入按追加块的顺序传递给块组成的“链条”。
1 | class MySequential(nn.Module): |
在__init__方法中,我们将每个块逐个添加到有序字典_modules中。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yeの博客!