李宏毅深度学习L4
GAN
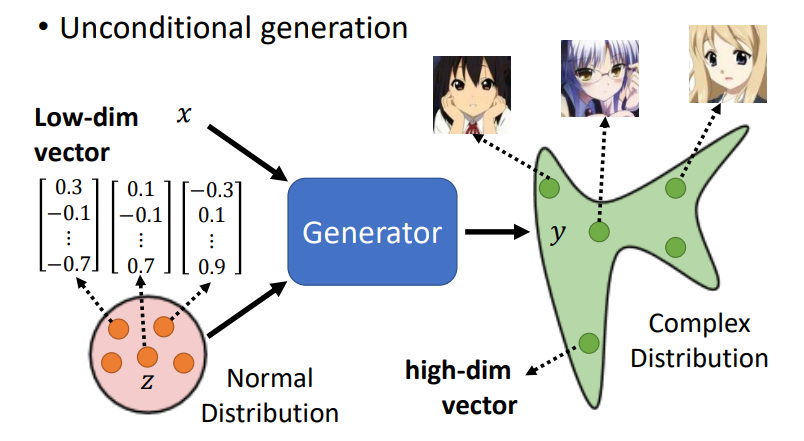
将网络作为生成器(Generator)
- 给定一个分布,从分布sample出一些样本
- 网络作为generator,可以接收sample出来的样本和输入x,学习到一个复杂的分布,输出y。
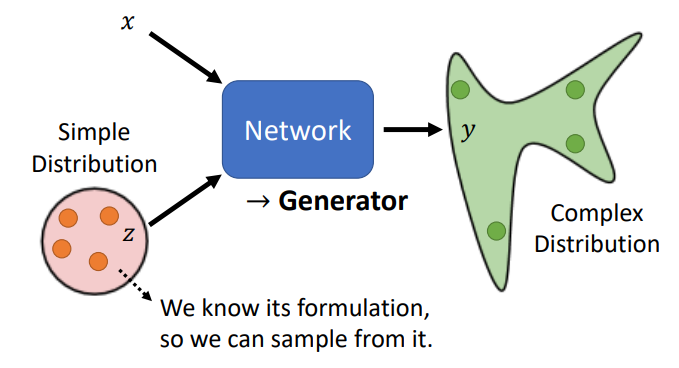
为什么需要一个分布
以一个Video Prediction为例子
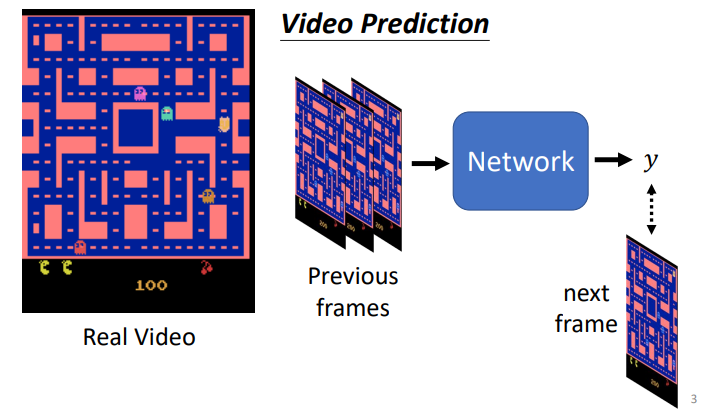
- 给定之前的帧,网络需要输出下一帧
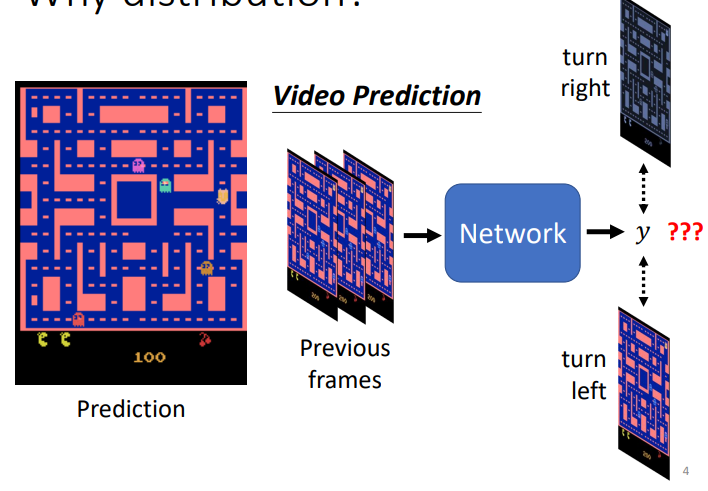
- 但是这样会出现一个问题,网络采用一个多分类问题的解决形式时,输出可能会结合多种可能性,生成一种包含所有情况,只是概率大小不同的图
- 在这个例子中,你会看到小豆子分裂,一个往左,一个往右,网络没办法只选定一种可能
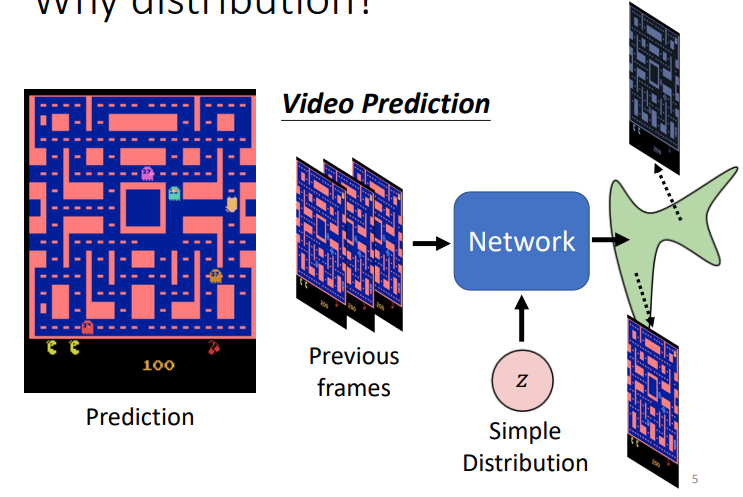
- 当给定一个分布sample出来的数值,网络便可以学习到一个分布,进行一个特定的选择
所有种类的GAN

https://github.com/hindupuravinash/the-gan-zoo
GAN的结构
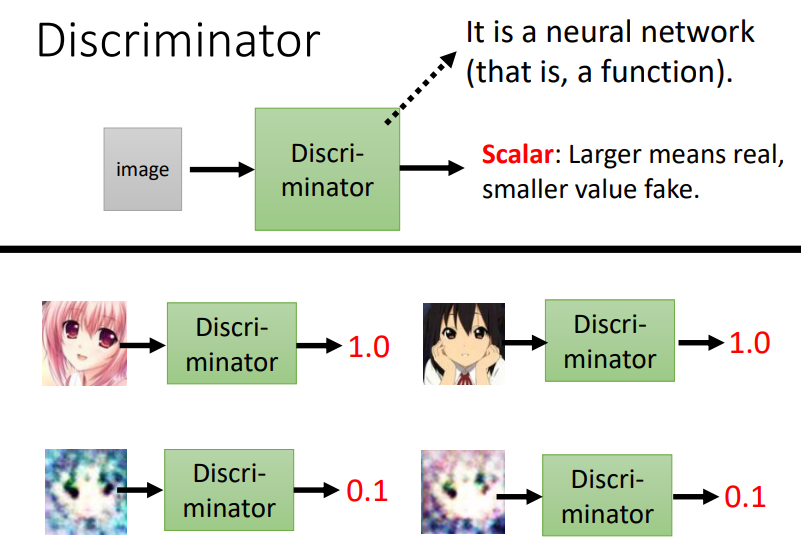
- GAN包括Generator和Discriminator两个结构
- Generator根据输入和sample来在一个复杂的分布中sample出一个输出
- Discriminator对于给定的输入,进行打分,判断其是否为真实的
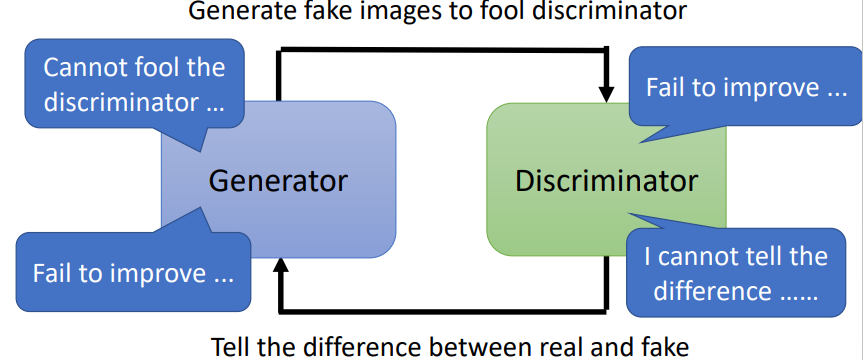
GAN的思想
- Generator想办法生成逼真的图片来骗过Discriminator
- Discriminator想办法辨别出真假图片
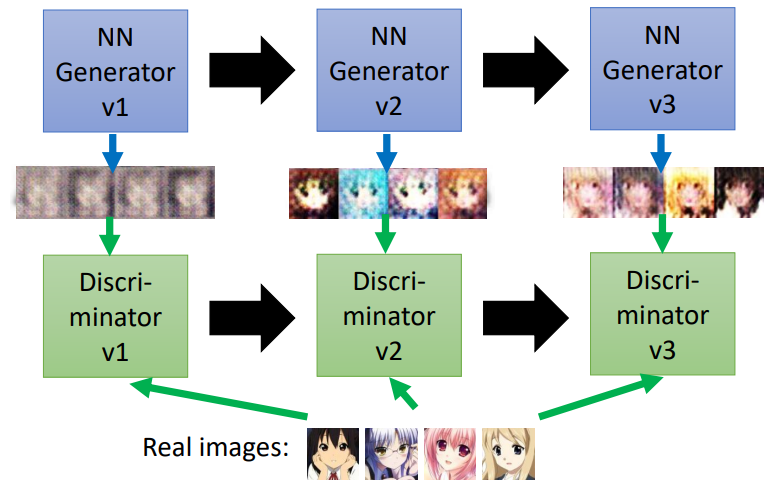
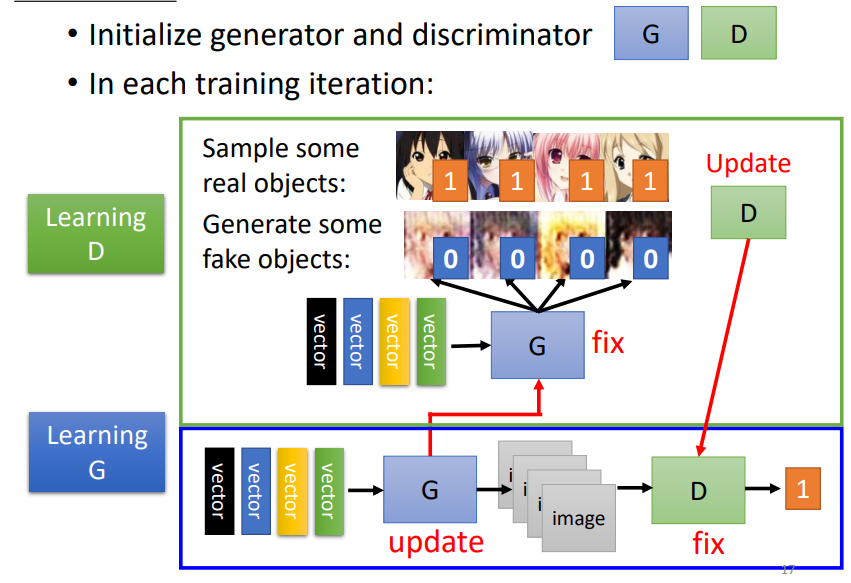
GAN的算法
- 初始化generator和discriminator
- 在每一个训练步骤中
Step1
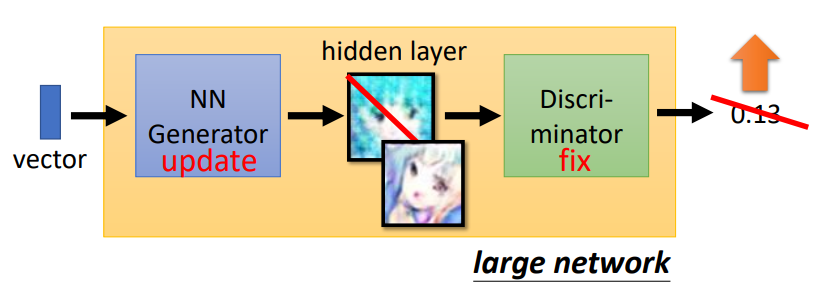
- 固定generator G,更新discriminator D
- Discriminator学习给真实的图片高分,给生成的图片低分,即学会去分辨真假图片
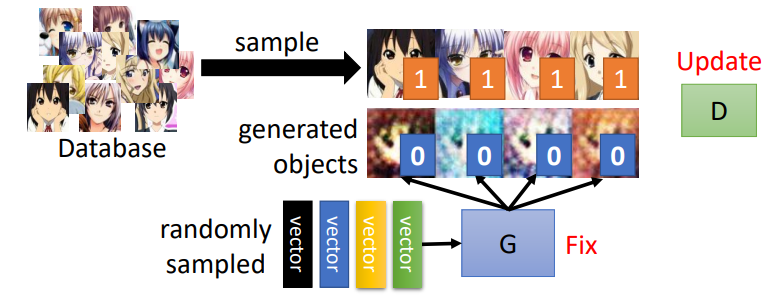
Step2
- 固定discrimator D,更新generator G
- Generator要学会去欺骗discriminator
GAN背后的理论
目标
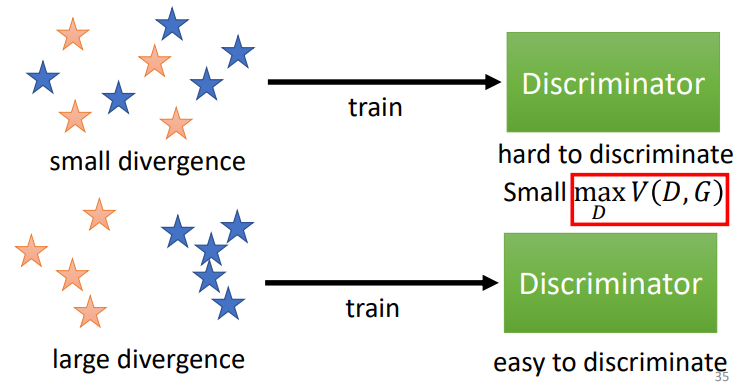
- 让Generator生成的分布尽可能向数据的分布靠近
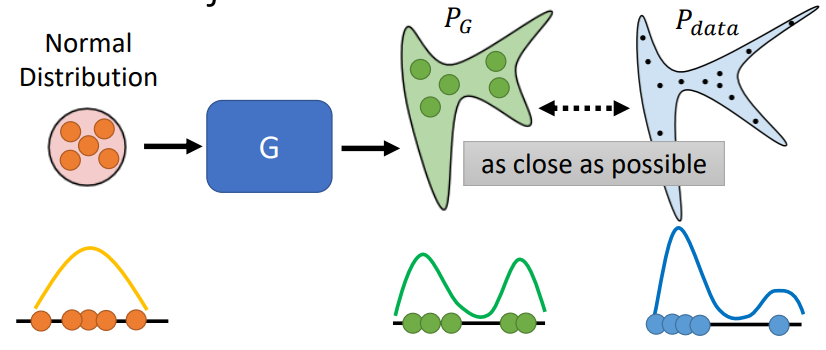
即 \[ G^* = arg\min_{G}Div(P_G,P_{data}) \] 这里的\(Div(P_G,P_{data})\)是指两个分布之间的divergence(散度)
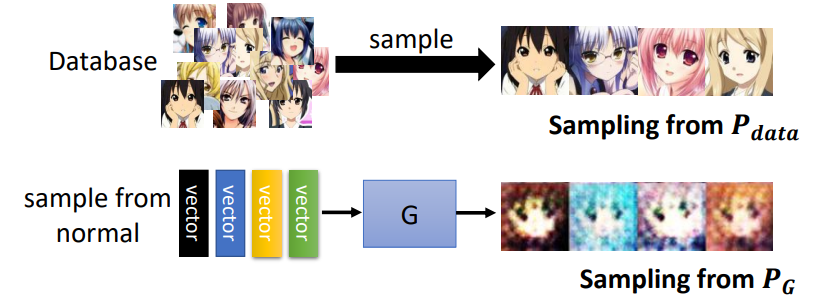
Sampling
尽管我们不能确切地知道\(P_G\)和\(P_{data}\)的分布,但是我们从两个分布中sample出一些样本
Discriminator
这里的Discriminator是一个二分类的分类器
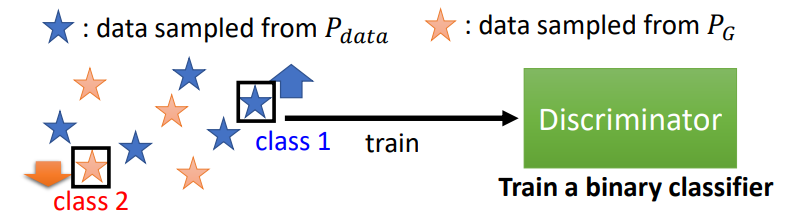
Training: \[ D^* = arg\max_{D}V(D,G) \] 其实后面的\(\max_DV(D,G)\)相当于一个JS散度
Objective Function: \[ V(G,D)=E_{y\sim P_{data}}[logD(y)]+E_{y\sim P_G}[log(1-D(y))] \] 其中,我们希望\(logD(y)\)能够尽可能地大,这样能够认出真实的图片;\(log(1-D(y))\)能够尽可能地小,这样可以辨别出生成地图片

我们可以将Generator中需要的散度换成Discriminator的目标函数,联合训练

其他的一些divergence

Tips for GAN
JS divergence并不适合GAN
在大部分情况下,\(P_G\)和\(P_{data}\)并不是重叠的(overlapped)
- 两者都是高维空间在低维空间的流形(manifold),重叠部分可以忽略
- 取样问题,尽管两者之间有重叠但是取样不够多的话
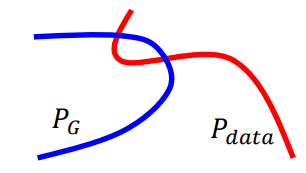
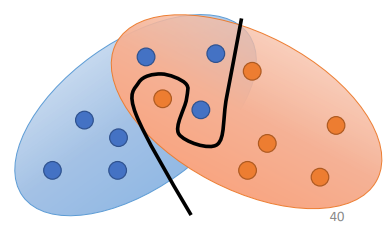
JS divergence的问题
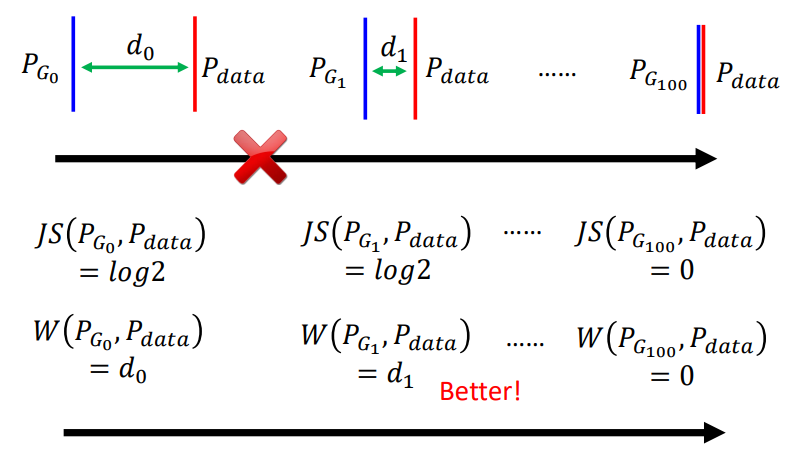
- 当两个分布不重叠的话,JS divergence总是\(log_2\)
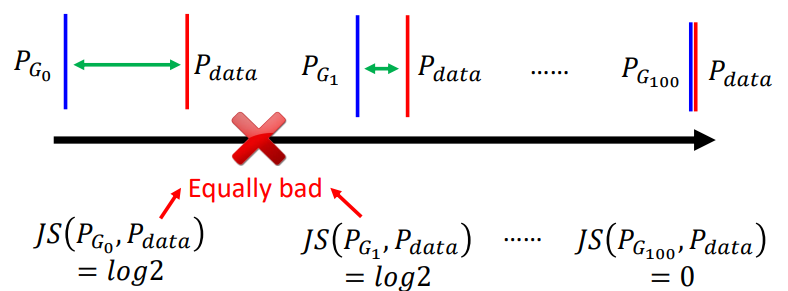
这样会出现一个很严重的问题,当两个分布不重叠的时候,discriminator总是会实现百分百精度的分类,但这样GAN的训练就无法有一个明确的方向去优化了,因为只要不重叠,都是一样差的
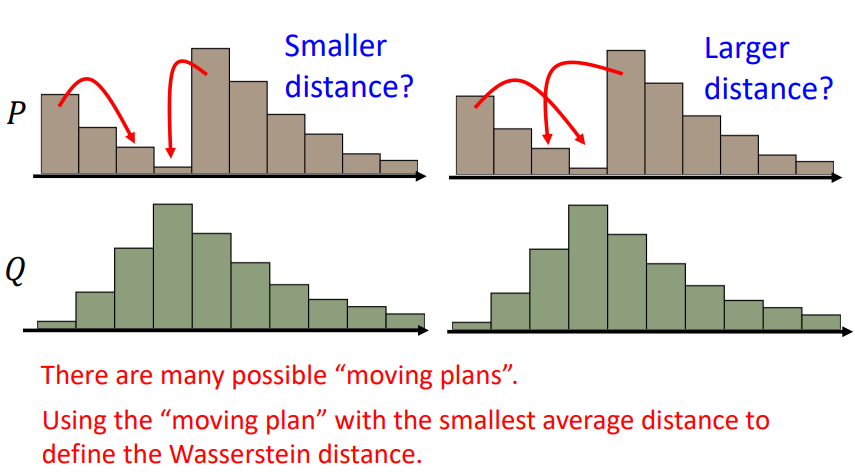
Wasserstein distance
Wasserstein distance可以用来衡量一个分布变换到目标分布的最小距离
这样GAN的优化就有一个明确的方向
WGAN
使用Wasserstein distance来优化\(P_{data}\)和\(P_G\)

如果没有D函数光滑的限制,D的训练将不会收敛
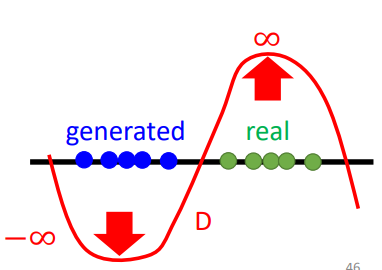
- 如上图所示,生成分布和数据分布没有重叠,discriminator可能会不断往无穷处进行打分,来更好地区分两者,无法收敛
- 让discriminator的函数保持光滑可以强制\(D(y)\)位于正无穷和负无穷之间
不同的做法
Origin WGAN -> Weight
强制参数w位于c和-c之间
参数更新后,如果\(w>c\),\(w = c\);如果\(w < -c\),\(w = -c\)
Improved WGAN -> Gradient Penalty 梯度惩罚
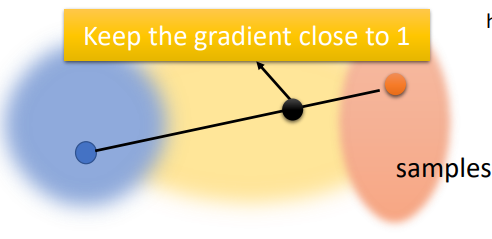
- Spectral Normalization->Keep gradient norm smaller than 1 everywhere
GAN仍然很难训练,Generator和Discriminator需要棋逢对手,不能有一方独大
用于序列生成的GAN
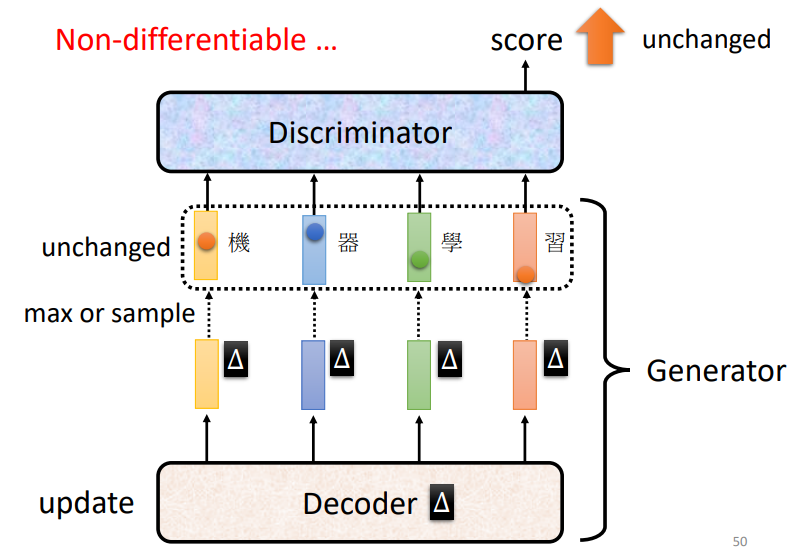
- 通常,generator是从一个从其他方法中学习的模型微调(fine-tuned)得到的
- 但是,通过足够的超参数调整和提示,ScarchGAN可以从头开始训练