pandasL1
Series和DataFrame
- 分别代表着一维的序列和二维的表结构
Series
- Series 是个定长的字典序列。说是定长是因为在存储的时候,相当于两个 ndarray
- Series有两个基本属性:index 和 values。
- 在 Series 结构中,index 默认是 0,1,2,……递增的整数序列,当然我们也可以自己来指定索引
1 | import pandas as pd |
Series内部的列表时基于numpy的array实现的
```python pd.Series([1, 2]).values
array([1, 2])
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#### DataFrame
- 包括了行索引和列索引,我们可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
```python
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80],
'English': [65, 85, 92, 88, 90],
'Math': [30, 98, 96, 77, 90]}
df1= DataFrame(data)
df2 = DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
数据清洗的一些操作
重命名列名 columns,让列表名更容易识别
- ```python df2.rename(columns={origin:change}) df2.columns.names = []
# 设置列索引名 df2.index,names = []
1
2
3
4
5
- **去重复的值**
- ```python
df.drop_duplicates()
- ```python df2.rename(columns={origin:change}) df2.columns.names = []
# 设置列索引名 df2.index,names = []
格式问题
- ```python df.column.astype(type)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- **数据间的空格**
- ```python
# 删除左右两边空格
df2['Chinese']=df2['Chinese'].map(str.strip)
# 删除左边空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
# 删除右边空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
# 去除$
df2['Chinese']=df2['Chinese'].str.strip('$')
# 大小写转换
# 全部大写
df2.columns = df2.columns.str.upper()
# 全部小写
df2.columns = df2.columns.str.lower()
# 首字母大写
df2.columns = df2.columns.str.title()
- ```python df.column.astype(type)
查找空值
```python df.isnull()
知道哪列存在空值
df.isnull().any() # 寻找非空值 df.notnull()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- **使用apply函数对数据进行清洗**
- ```python
df['name'] = df['name'].apply(str.upper)
def double_df(x):
return 2*x
df1[u'语文'] = df1[u'语文'].apply(double_df)
def plus(df,n,m):
df['new1'] = (df[u'语文']+df[u'英语']) * m
df['new2'] = (df[u'语文']+df[u'英语']) * n
return df
df1 = df1.apply(plus,axis=1,args=(2,3,))

读取CSV文件
1 | fixed_df = pd.read_csv('../data/bikes.csv', |
- 可以将某些列转换成日期
- dayfirst将日期的列提前
- encoding解码方式
查看DataFrame的信息
查看行数和列数
1 | df.shape |
删除 DataFrame 中的不必要的列或行
1 | df.drop(columns=[]) |
apply函数的使用
跟lambda函数一起使用
可以改变某列的数据类型
- ```python dollarizer = lambda x: float(x[1:-1]) chipo.item_price =
chipo.item_price.apply(dollarizer)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
### 对DataFrame的行进行操作
#### 查看前几行的数据
```python
# 显示前五行
# 切片
df[:5]
# loc
df.loc['index1':'index5', :]
# iloc
df.iloc[:5, :]
- ```python dollarizer = lambda x: float(x[1:-1]) chipo.item_price =
chipo.item_price.apply(dollarizer)
在loc和iloc中使用切片选中时,不需要加列表外套,除非选择几个需要整合成一个列表
丢弃某一行数据
丢弃数据全为NaN的行
1 | df = df.dropna() |
丢弃数据全为0的行
1 | # 找到全为0的行 |
对DataFrame中的列进行操作
选取一列以及多列
1 | # 有两种,如果列名中有空格只能用第一种 |
对一列进行绘图
1 | # 默认是折线图 |
对列进行计数
1 | df['column'].value_counts() |
- 会忽略NaN值
- 计数结果会进行排序,但是两个计数结果进行算术操作时,会按正确对应关系进行操作
选取符合条件的列
1 | df1 = df[df.column == condition] |
利用Counter对DataFrame中的一列进行计数
1 | x = df.item_name |
- pd.DataFrame.from_dict()可将Counter类型转换成DataFrame
改变DataFrame中列的顺序
可以通过选取列,重新组织顺序
1 | df1 = df[['name', 'type', 'hp', 'evolution', 'pokedex']] |
改变DataFrame中列的名字
可以直接对df.columns赋值一个列表
1 | df1.columns = ['alcohol', 'malic_acid', 'alcalinty_of_ash', 'magnesium', |
NaN值的操作
填充DataFrame中的NaN值
1 | df.fillna(1, inplace=True) # 将NaN全部填充为1 |
删除带有NaN值的行
1 | df=df.dropna(how='any') |
Parameters 说明 axis 0为行 1为列,default 0,数据删除维度 how {‘any’, ‘all’}, default ‘any’, any:删除带有nan的行;all:删除全为nan的行 thresh int,保留至少 int 个非nan行 subset list,在特定列缺失值处理 inplace bool,是否修改源文件
DataFrame的索引
DataFrame重新设置索引
1 | df = df.reset_index(drop=True) |
- drop=True会将原来的索引舍弃
DataFrame的多级索引
1 | df = pd.DataFrame(np.random.randint(80, 120, size=(6, 4)), |
多级索引的排序
1 | df.columns.names = ['Language', 'Pass'] # 设置列索引名 |
多级索引轴向转换
stack(): 将行索引变成列索引,可以理解为将表格数据转换为树状数据unstack(): 将列索引变成行索引,可以理解为将树状数据转换为表格数据- 两个函数互为逆函数,作用相反,用法相同。单级索引时,结果会生成一个Series;多级索引时默认转换最内层索引,也可以自定义转换的索引层级
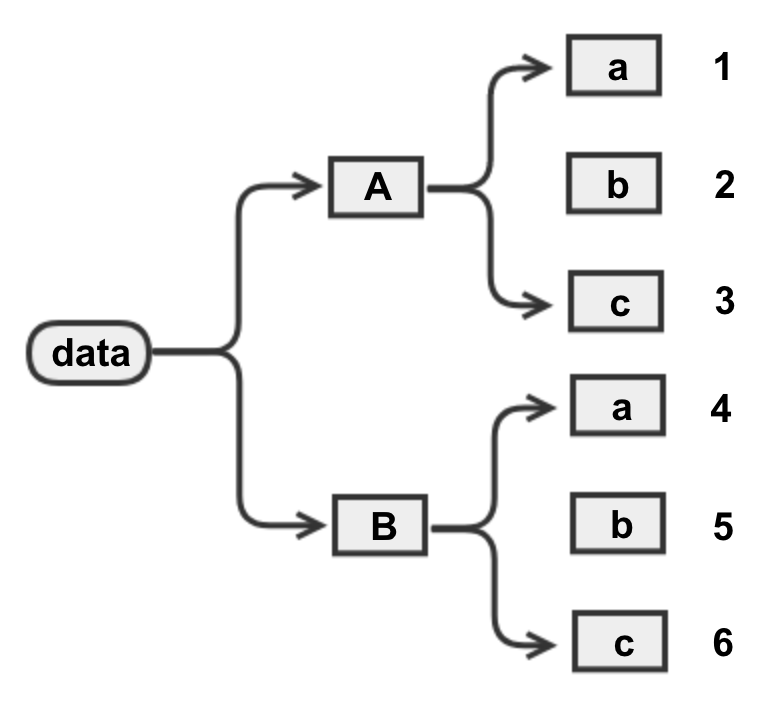
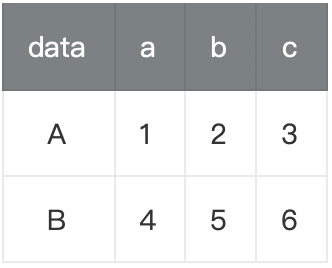
获取股票数据
使用alpha_vantage
1 | import pandas as pd |
key=WRB3PU9PRGSGVS2H
symbol是获取股票的名称,interval是时间间隔
- interval取值:1min
,5min,15min,30min,60min
- interval取值:1min
使用pandas_datareader.data
1 | import pandas_datareader.data as web |
DataFrame的合并
concat
1 | pd.concat([df1,df2,df3],axis=0,ignore_index=True) |
- 参数axis=0表示上下合并,1表示左右合并,ignore_index=True表示忽略原来的索引
- join参数
- join为‘inner’时 会裁剪吊互相之间没有的数据,
- join为‘outer’时 会用NaN值来填充相互之间没有的数据
merge
1 | pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, |
append
1 | df.append(df1) |
当索引为日期时
获取索引代表的星期数
1 | df.index.weekday |
- 同理可得到月的、年的等
将属性改变成datetime
- 使用pd.to_datetime对列或者索引进行改变
1 | df.index = pd.to_datetime(df.index) |
改变时间频率
- 改变为每一周、每个月,每个年等
- 使用df.resample('Y')
- Y是年,M是月,W是周
1 | # 一个月一个月频率的DataFrame |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Yeの博客!